春风好媒妁,说动一树榴红。偶来雨多,茅屋又新破,且戴一笠,借故去访邻居家老叟。 循着江岸梅林,一颗颗睡饱了的梅子,正是青里一抹红透,得着此刻无人,且摘它个两袖清风、一袋新酒。世间的功名不能裱壁,就向天地讨一笔闲钱糊口。正算计着老叟家的那只古瓮,怎么着,一匹快马驰过,溅得我一身泥泞,定睛一探,可不是城里那位篡了功名的新进?且拼春风一叹,还好,近日雨多。
电子设备、互联网大行其道的的今天,你还有多少空余时间去熟悉、了解身边的人呢?日益增长的互联网泡沫又始于何时?了解身边的人,从了解身边互联网的浏览器开始。
浏览器的主要功能就是向服务器发出请求,在浏览器窗口中展示 HTML 文档、PDF、图片、视频等网络内容。这些网络资源的位置由用户使用 URI(统一资源标示符)来指定指定。
或许在大多数人眼中,浏览器是这样的:

一个展示前端,一个未知的中间层连接着网络世界;甚至,网络世界也可以省略:一台显示器,一个神秘的幕后黑盒。
如果你是一个前端开发者,甚至每天浏览器陪伴你度过的时光比女朋友陪伴你的都要久,想想那每一个令人“不是那么期待”的早晨,每一个争分夺秒完成任务的黄昏,只有浏览器和编辑器一直是你忠实的伙伴。而就连你一直离不开的 VS Code 编辑器,甚至也与浏览器有着莫大的渊源。
屏幕前的朋友,你熟悉自己身边的那些人吗,熟悉那些与你朝夕相伴的朋友吗?也许熟悉,也许不,那么,你是否愿意花些时间来熟悉一下这个在大量时间里与你有着莫大交集的浏览器的内心世界呢?
今天,我们就来一探究竟,走进这个我们与网络连接最紧密的中间地带。全文行文结构大概如下:
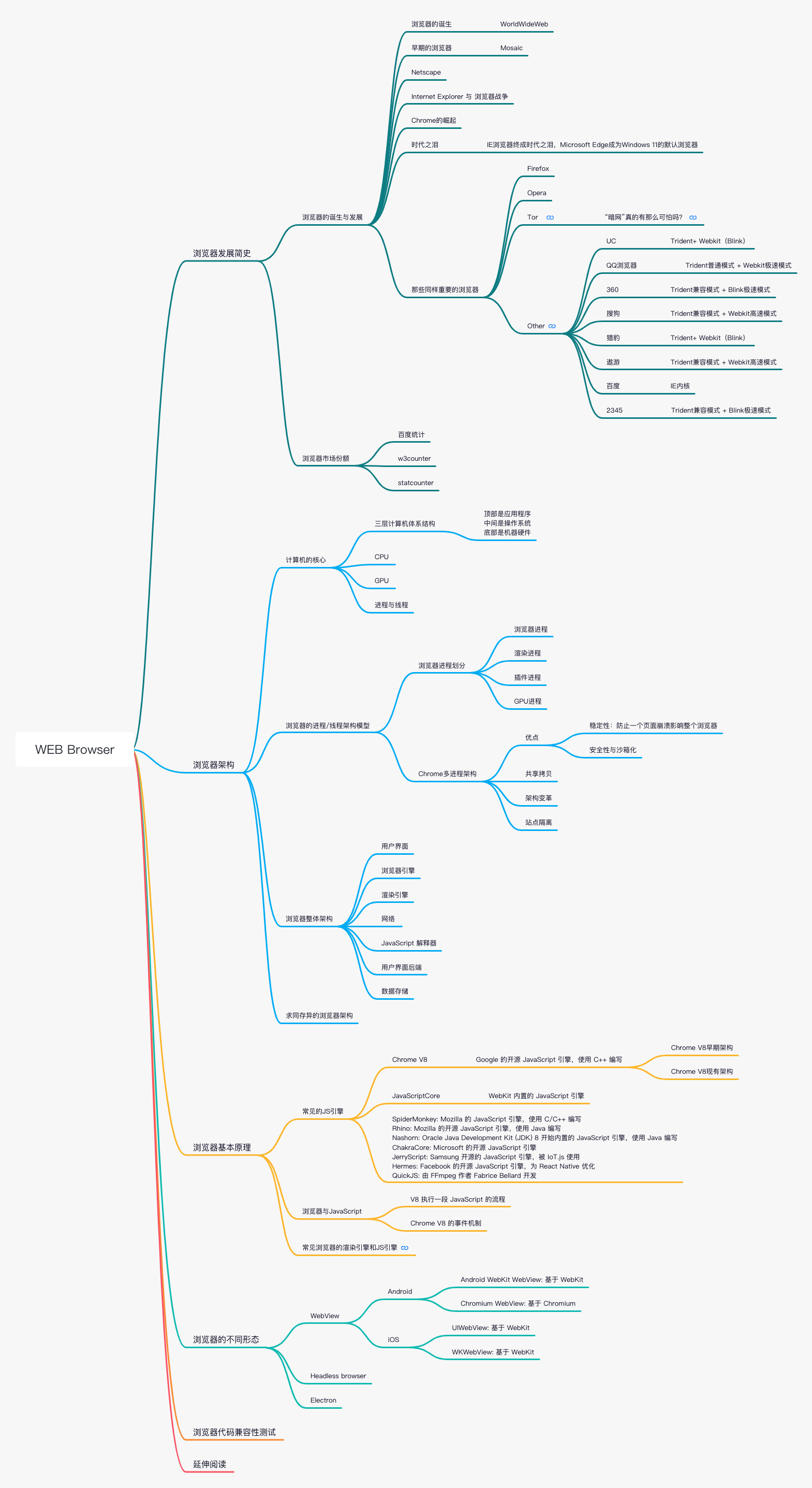
浏览器发展简史
浏览器的诞生与发展
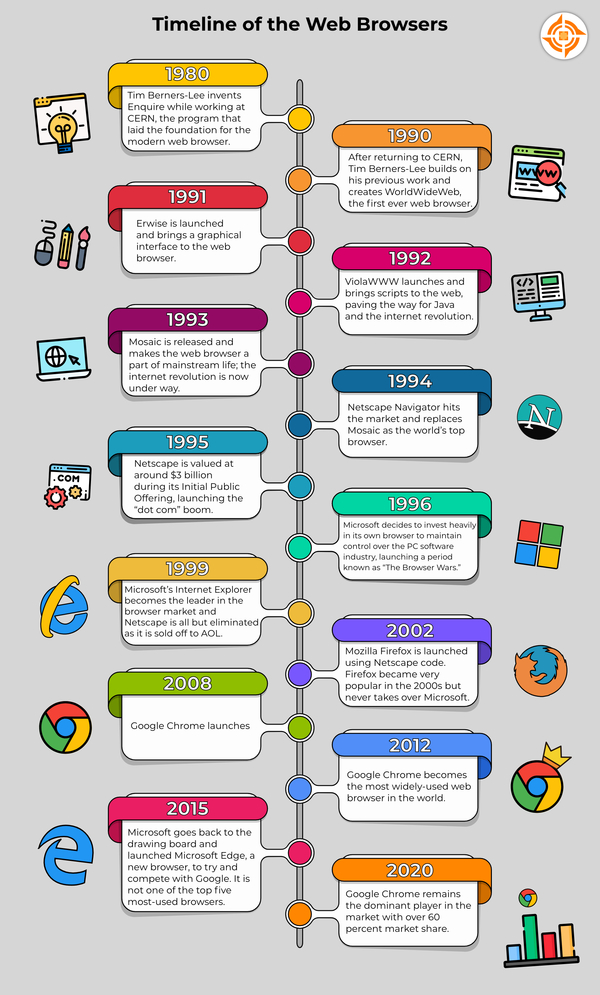
也许你知道,第一款浏览器 —— WorldWideWeb,诞生于 1990 年。但是现代浏览器的雏形却孕育于 1980s 年代。
一位名叫蒂姆·伯纳斯-李的英国科学家在 1980 年代初期创建了一个名为 Enquire 的计算机程序,当时他在总部位于瑞士的欧洲核研究组织(CERN,以其法文字母表示)工作。该计划旨在使在 CERN 工作的许多不同个人更容易共享信息。
1990 年,第一款浏览器问世于 Tim Berners-Lee 在 CERN 工作期间。您可能想知道 Web 浏览器到底是什么,简而言之,它是一个计算机程序,其目的是显示和检索数据。使用分配给存储在网络服务器上的每个数据集(网页)的 URL,它可以做到这一点。所以这意味着当您在浏览器中输入内容时,您实际上是在输入地址,浏览器将使用该地址来获取您想要查看的信息。浏览器的另一个关键功能是以易于理解的方式向您解释和呈现计算机代码。
下图简单罗列了截止 2020 年浏览器的发展简史:
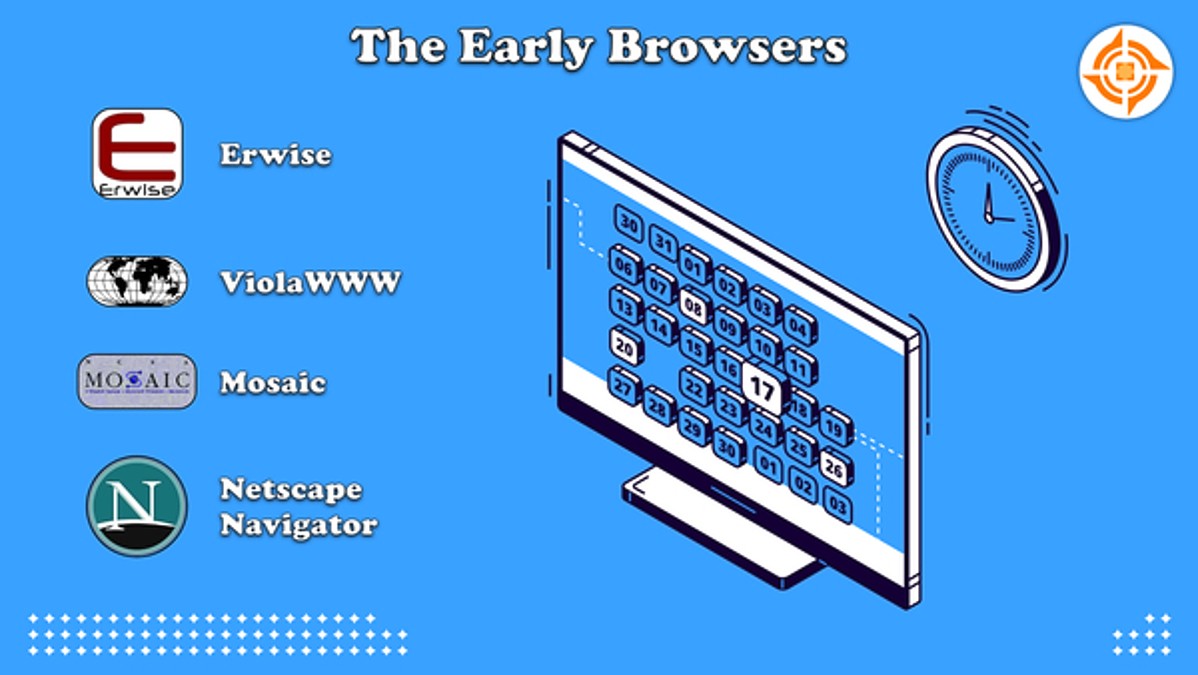
早期比较有名、有意义的浏览器主要包括 Erwise、ViolaWWW、Mosaic、Netscape Navigator:
1990 年浏览器诞生之后的故事,想必您已经早有耳闻:
-
NCSA Mosaic,或简称 Mosaic,是互联网历史上第一个获普遍使用和能够显示图片的网页浏览器。它由伊利诺伊大学厄巴纳-香槟分校的 NCSA 组织在 1993 年发表,并于 1997 年 1 月 7 日正式终止开发和支持,这款浏览器在当时大受欢迎。Mosaic 的出现,算是点燃了后期互联网热潮的火种之一。后来 Netscape Navigator 浏览器的开发,聘用了许多原有的 Mosaic 浏览器工程师,但是没有采用 Mosaic 网页浏览器的任何代码。而传承网景浏览器代码的后裔为 Firefox 浏览器。
-
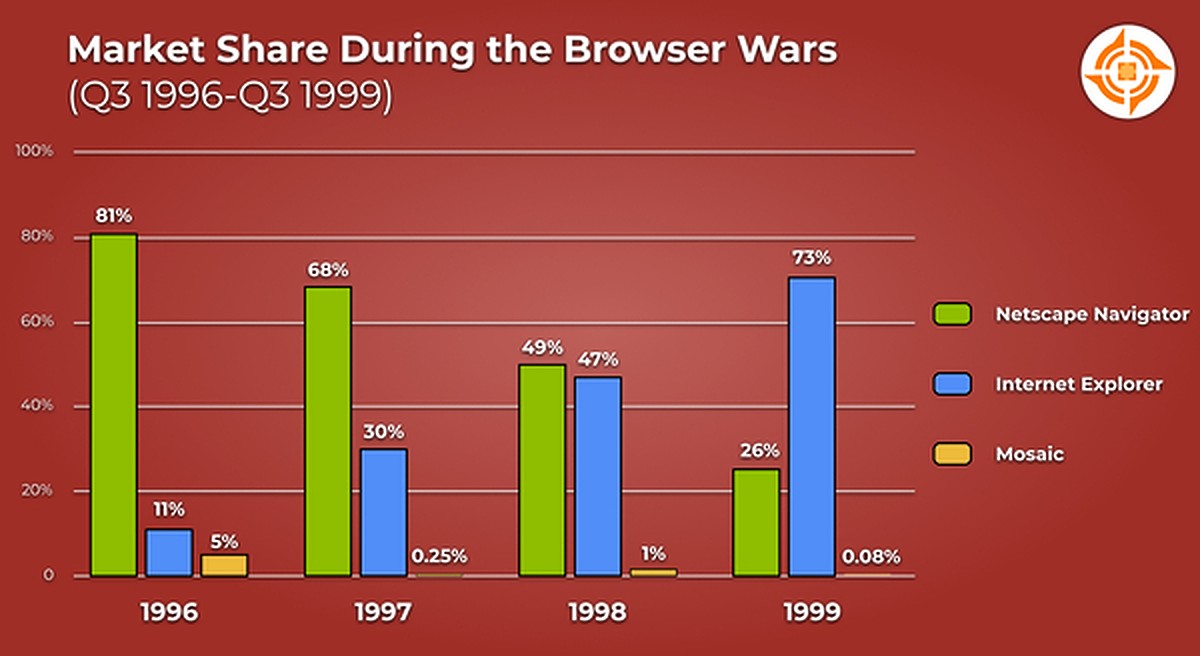
Marc Andreesen 与同事 Jim Clark 于 1994 年成立了一家公司,当时 Mosaic 还是最流行的浏览器,它们计划打造出一个比 Mosaic 更好的浏览器,占领市场,让他们变得富有,并改变历史。他们的第一个浏览器被称为 Mosaic Netscape 0.9,不久更名 Netscape。得益于 JavaScript(JavaScript 诞生于 1995 年,它是 Netscape 的 Brendan Eich 仅花费十天设计实现的。) 和“partial-screen loading”(即使页面未完全加载,用户也可以开始阅读页面上的详细信息,这一个新概念极大地丰富了在线体验)等功能,它很快成为市场领导者,占据了浏览器市场上一半的份额,最疯狂的时候,网景浏览器的市场份额接近百分之九十。
1995 年 8 月 9 日,网景公开募股,最初的价格是 14 美元一股,但后来阴差阳错,改为 28 美元一股发行,当天收盘时,网景的股票成了 75 美元一股,网景成为了当时世界上市值最高的互联网公司,Netscape 的 IPO 也助长了日益增长的网络泡沫。
- Netscape 最初的成功向那些在计算机和互联网领域工作的人证明时代已经永远改变了,这让当时业内最强大的参与者感到震惊,一家名为 Microsoft 的西雅图公司就是其中之一。计算机将通过浏览器运行,浏览器可以在任何机器上运行,从而使软件行业民主化并降低其相当大的进入壁垒,这导致许多人猜测操作系统的时代已经结束。Netscape 对微软来说是一个挑战,微软在 1990 年代后期创建了自己的浏览器 Internet Explorer,当时的 IE 和现在一样,通常被视为劣质产品。由于微软已经建立了销售其专有操作系统 Windows 的帝国,因此将这种由 Netscape 等公司带头的发展视为一种威胁。微软通过对其产品的大量投资,使其与 Netscape 一样好,成功地迅速扭转了浏览器行业的局面。Windows 计算机在发布时已经安装了 Internet Explorer(Microsoft 的浏览器),这使其能够在市场上占据一席之地并不断发展壮大,最终在浏览器领域取得了胜利,这便是著名的第一次浏览器大战。
市场份额的快速下滑导致 Netscape 被出售给了 AOL,2003 年 7 月,网景解散,就在解散的当天,Mozilla 基金会成立,2004 年基于 Mozilla 源码的 Firefox 首次登台,拉开了第二次浏览器大战的序幕。2008 年 Netscape 最终灭绝,当年的浏览器帝国正式退出了历史的舞台。
到 2003 年,微软的 Internet Explorer 控制了 92% 以上的市场,完全扭转了 1995 年的局面。然而,虽然微软在不到十年的时间里成功地完全接管了浏览器市场,但很快就会出现其他竞争,再次重塑网络浏览器的历史。
-
微软在 1990 年代后期崛起并让 Netscape 等公司屈服之后,浏览器的历史似乎已经走到了尽头。然而,正如最初发布后的情况一样,Internet Explorer 正在成为劣质产品。谷歌于 2008 年推出了其专有浏览器——Chrome。到 2012 年底,即推出仅四年后,谷歌 Chrome 浏览器凭借其易用性、跨平台功能、速度以及与标签和书签相关的特殊功能,取代 Internet Explorer 成为最受欢迎的浏览器。
-
在 2000 年代初期,可能是在微软将浏览器附加到其操作系统之后,Apple 发布了 Safari,一种专为 Mac 设计的浏览器,并成为目前市场上第二大浏览器。
-
Internet Explorer 的流行度在 2000 年代后期逐渐减少,主要是因为它变得缓慢和过时,而 Microsoft 发现自己现在似乎已经是在外面观察浏览器世界。该公司不想继续错过,于是着手解决这个问题,但发现一个关键问题是“Internet Explorer”这个名字已经成为劣质浏览器的同义词。因此,为了尝试重新进入游戏,微软不得不重新命名,是以,Edge 便诞生了。Edge 是微软浏览器的最新版本,它受到了很多好评,但对于 Microsoft 来说,Edge 的出现可能为时已晚。
-
IE 浏览器终成时代之泪,Microsoft Edge 成为 Windows 11 的默认浏览器。这是 Windows 系统更新 20 年来,IE 的首次缺席,也是最后一次。早在 Win10 更新时微软就表示,将放弃更新 IE 转向开发新的浏览器 Microsoft Edge。如今是彻底要和桌面上的 IE 说再见了。 —— IE 浏览器将从 Windows 11 中消失,它也将在 2022 年安息。
浏览器市场份额
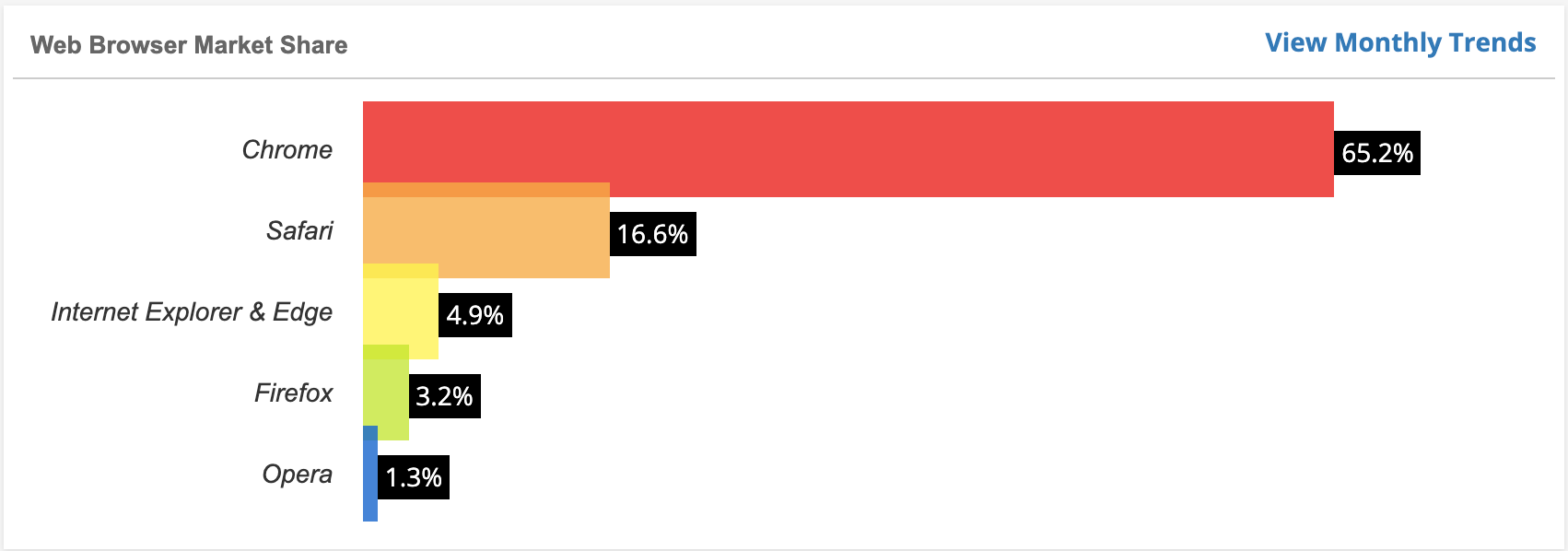
截止 2021 年 7 月初,浏览器市场份额如下所示。
浏览器使用趋势变化:
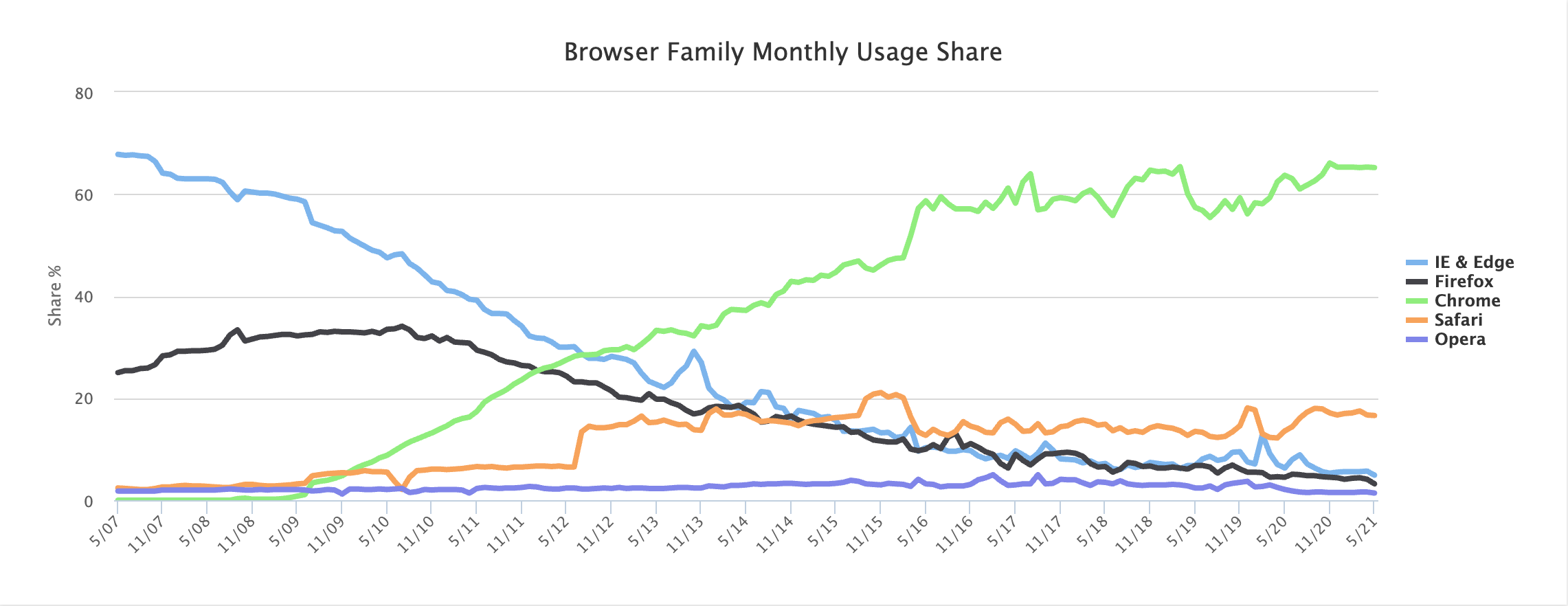
浏览器市场份额:
国内浏览器市场份额:
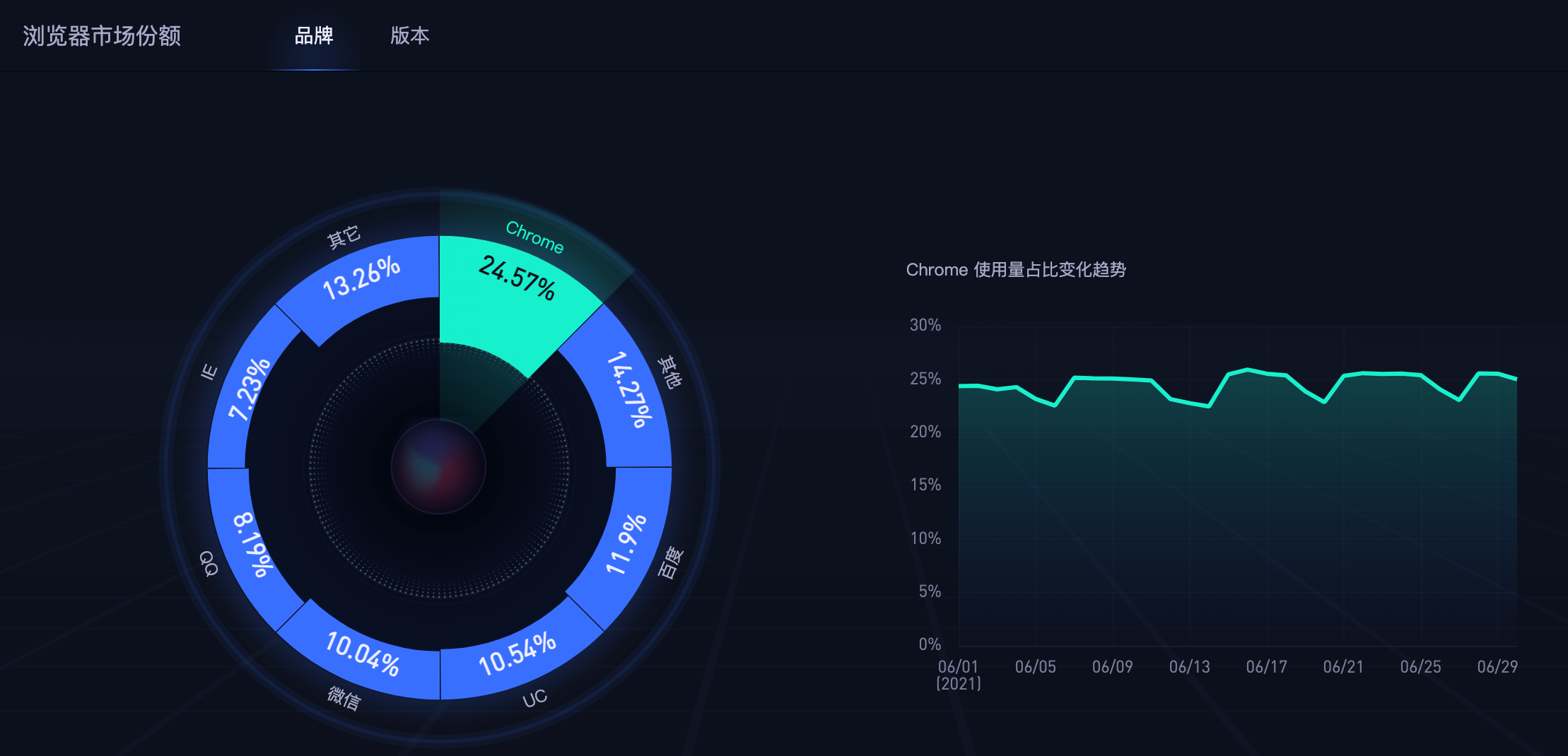
如果你对以上浏览器市场份额数据有兴趣,可以通过以下链接进行查看:
浏览器架构
计算机的核心
三层计算机体系结构:底部是机器硬件,中间是操作系统,顶部是应用程序。
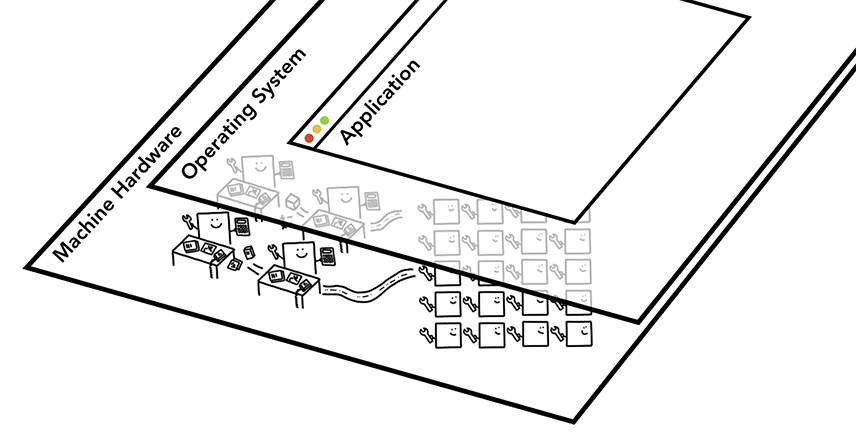
当你在电脑或手机上启动应用时,是 CPU 和 GPU 为应用供能。通常情况下应用是通过操作系统提供的机制在 CPU 和 GPU 上运行。
CPU
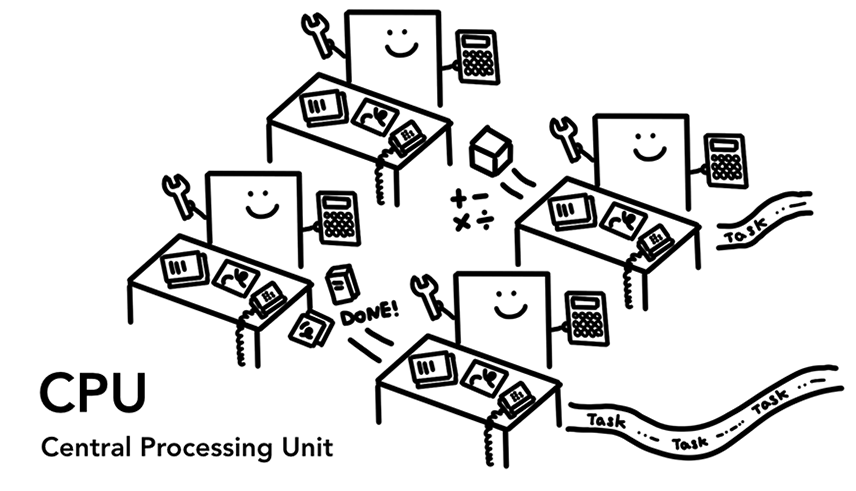
中央处理器(Central Processing Unit),或简称为 CPU。CPU 可以看作是计算机的大脑。一个 CPU 核心如图中的办公人员,可以逐一解决很多不同任务。它可以在解决从数学到艺术一切任务的同时还知道如何响应客户要求。过去 CPU 大多是单芯片的。随着现代硬件发展,你经常会有不止一个内核,为你的手机和笔记本电脑提供更多的计算能力。
4 个 CPU 核心作为办公人员,坐在办公桌前处理各自的工作:
GPU
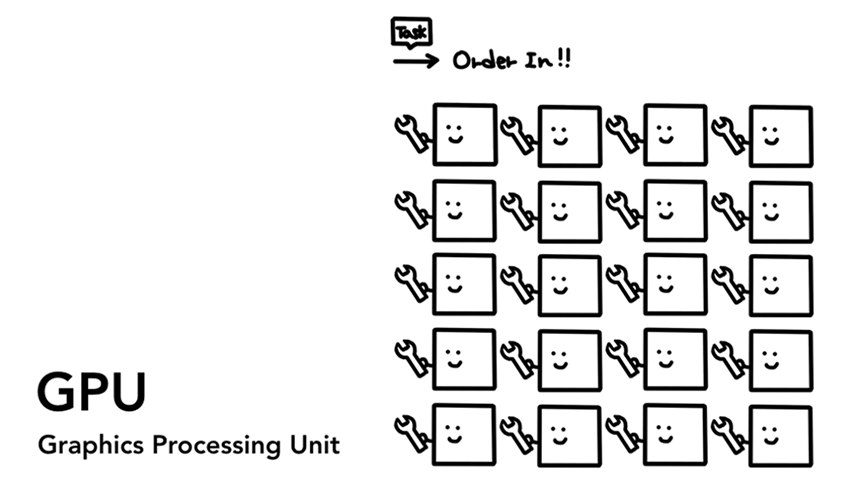
图形处理器(Graphics Processing Unit,简称为 GPU)是计算机的另一部件。与 CPU 不同,GPU 擅长同时处理跨内核的简单任务。顾名思义,它最初是为解决图形而开发的。这就是为什么在图形环境中“使用 GPU” 或 “GPU 支持”都与快速渲染和顺滑交互有关。近年来随着 GPU 加速计算的普及,仅靠 GPU 一己之力也使得越来越多的计算成为可能。
下图中,许多带特定扳手的 GPU 内核意味着它们只能处理有限任务。
进程与线程
进程可以被描述为是一个应用的执行程序。线程是位于进程内部并执行其进程程序的任意部分。
启动应用时会创建一个进程。程序也许会创建一个或多个线程来帮助它工作。操作系统为进程提供了一个可以使用的“一块”内存,所有应用程序状态都保存在该私有内存空间中。关闭应用程序时,相应的进程也会消失,操作系统会释放内存(下图中,边界框为进程,线程作为抽象鱼在进程中游动)。

进程可以请求操作系统启动另一个进程来执行不同的任务。此时,内存中的不同部分会分给新进程。如果两个进程需要对话,他们可以通过进程间通信(IPC)来进行。许多应用都是这样设计的,所以如果一个工作进程失去响应,该进程就可以在不停止应用程序不同部分的其他进程运行的情况下重新启动。

浏览器的进程/线程架构模型
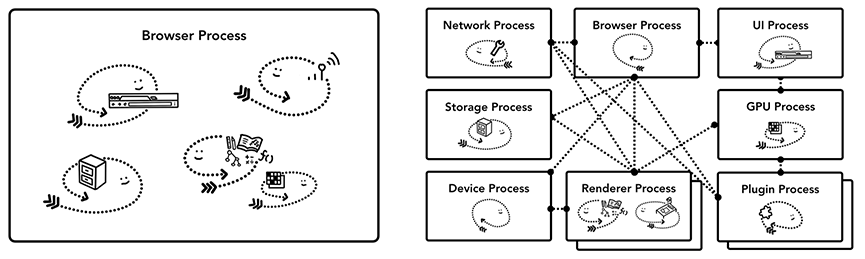
浏览器进程分类
关于如何构建 web 浏览器并不存在标准规范,一个浏览器的构建方法可能与另一个迥然不同。不同浏览器的进程/线程架构一般由下图几部分:
Chrome 多进程架构
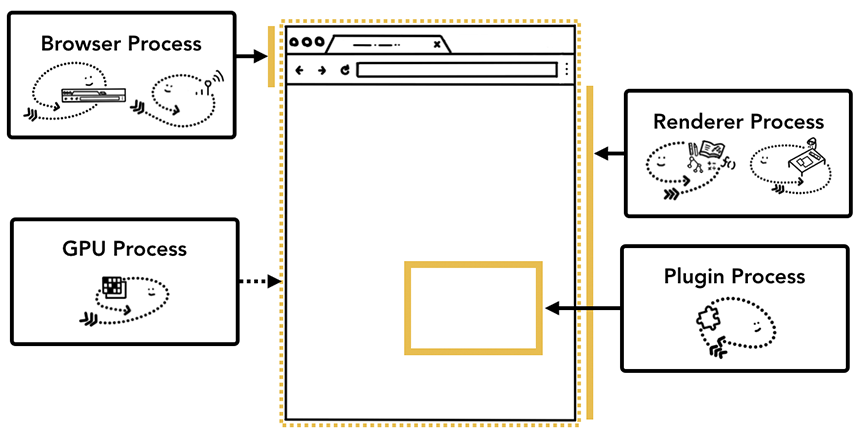
而当下“浏览器世界的王者” Chrome 架构如下图所示,渲染进程下显示了多个层,表明 Chrome 为每个标签页运行多个渲染进程。
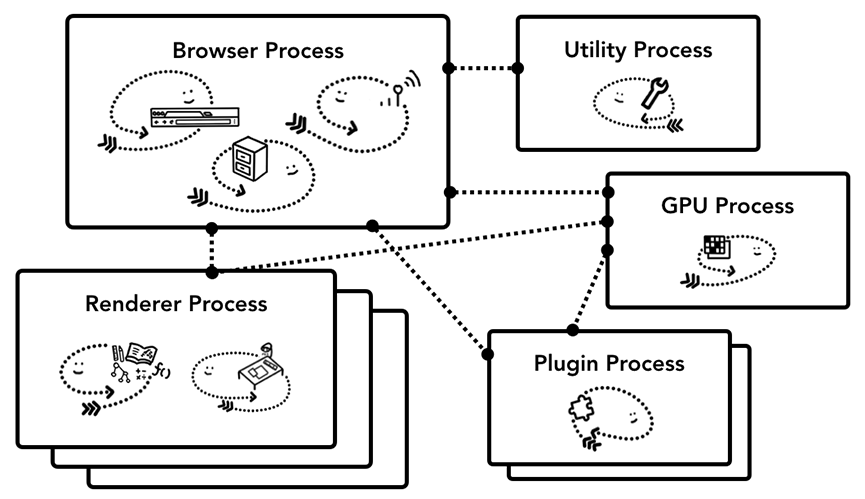
上图中,顶部是浏览器进程,它与处理应用其它模块任务的进程进行协调。对于渲染进程来说,创建了多个渲染进程并分配给了每个标签页。Chrome 在可能的情况下会给每个标签页分配一个进程。而现在它试图给每个站点分配一个进程,包括 iframe。
- 浏览器进程:控制应用中的 “Chrome” 部分,包括地址栏,书签,回退与前进按钮,以及处理 web 浏览器中网络请求、文件访问等不可见的特权部分;
- 渲染进程:控制标签页内网站展示;
- 插件进程:控制站点使用的任意插件,如 Flash;
- GPU 进程:处理独立于其它进程的 GPU 任务。GPU 被分成不同进程,因为 GPU 处理来自多个不同应用的请求并绘制在相同表面。
可以简单理解为不同进程对应浏览器 UI 的不同部分:
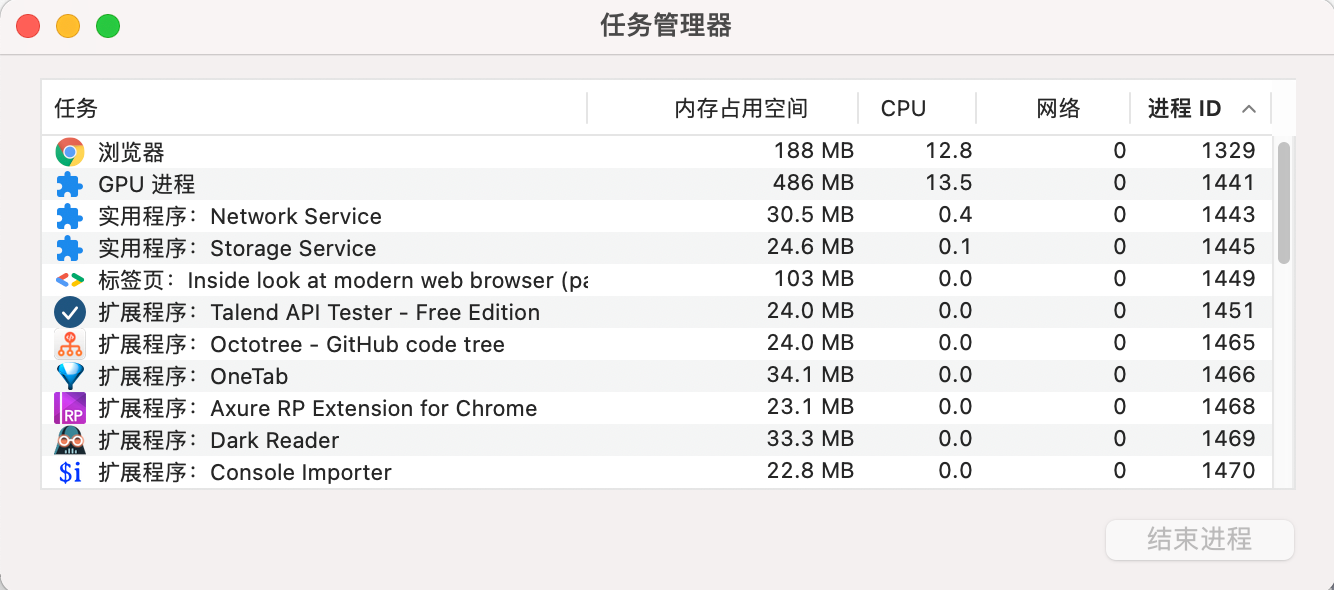
Chrome 更多的是把自己抽象为一个操作系统,网页或扩展相当于一个个程序,你甚至可以发现,Chrome 确实自带了一个任务管理器,在任务管理器面板会列出当前正在运行的进程以及它们当前的 CPU/内存使用量情况等信息。
一般你可以通过两种方法打开 Chrome 任务管理器:
- 通过在浏览器顶栏(标签 tab 栏)右侧右键,选择任务管理器查看;
- 点击 Chrome 浏览器右上角的“选项”菜单(一般是三个点的标识),选择“更多工具”子菜单,点击“任务管理器”,打开任务管理器窗口。
前文中提到了 Chrome 使用多个渲染进程,那他有什么优势呢?
- 稳定性:最简单的情况下,你可以想象每个标签页都有自己的渲染进程。假设你打开了三个标签页,每个标签页都拥有自己独立的渲染进程。如果某个标签页失去响应,你可以关掉这个标签页,此时其它标签页依然运行着,可以正常使用。如果所有标签页都运行在同一进程上,那么当某个失去响应,所有标签页都会失去响应,显然这样的体验会很糟糕。下面是多/单进程架构的对比动图,供你参考。

- 安全性与沙箱化:把浏览器工作分成多个进程的另一好处是安全性与沙箱化。由于操作系统提供了限制进程权限的方法,浏览器就可以用沙箱保护某些特定功能的进程。例如,Chrome 浏览器可以限制处理用户输入(如渲染器)的进程的文件访问的权限。
由于进程有自己的私有内存空间,所以它们通常包含公共基础设施的拷贝(如 Chrome V8 引擎)。这意味着使用了更多的内存,如果它们是同一进程中的线程,就无法共享这些拷贝(同一个进程中的线程不共享堆栈,堆栈是保证线程独立运行所必须的)。为了节省内存,Chrome 对可启动的进程数量有所限制。具体限制数值依设备可提供的内存与 CPU 能力而定,但是当 Chrome 运行时达到限制时,会开始在同一站点的不同标签页上运行同一进程。
Chrome 正在经历架构变革,它转变为将浏览器程序的每一模块作为一个服务来运行,从而可以轻松实现进程的拆解或聚合。具体表现是,当 Chrome 运行在强力硬件上时,它会将每个服务分解到不同进程中,从而提升稳定性,但是如果 Chrome 运行在资源有限的设备上时,它会将服务聚合到一个进程中从而节省了内存占用。在这一架构变革实现前,类似的整合进程以减少内存使用的方法已经在 Android 类平台上使用。

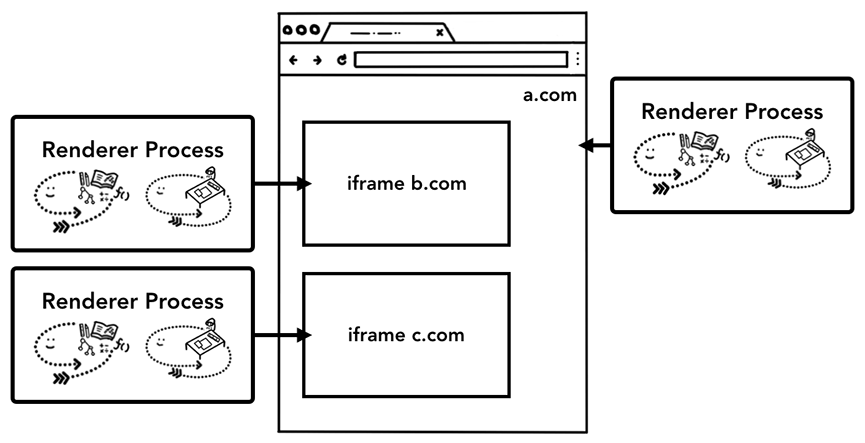
Chrome 67 版本后,桌面版 Chrome 都默认开启了站点隔离,每个标签页的 iframe 都有一个单独的渲染进程。启用站点隔离是多年来工程人员努力的结果。站点隔离并不只是分配不同的渲染进程这么简单。它从根本上改变了 iframe 的通信方式。在一个页面上打开开发者工具,让 iframe 在不同的进程上运行,这意味着开发者工具必须在幕后工作,以使它看起来无缝。即使运行一个简单的 Ctrl + F 来查找页面中的一个单词,也意味着在不同的渲染器进程中进行搜索。你可以看到为什么浏览器工程师把发布站点隔离功能作为一个重要里程碑!
延伸阅读:Chrome 为什么多进程而不是多线程?
浏览器整体架构
如果您是一名前端工程师,那么,面试时你大概率会被问到过:从 URL 输入到页面展现到底发生了什么?,如果您对这一过程不太熟悉,建议看看下面两篇文章,在此不过多赘述:
浏览器的主要任务之一就是渲染展示页面,不同的浏览器内核,渲染过程也不完全相同,但大致流程都差不多,下面这张图片是火狐浏览器(Firefox,可以认为是 Netscapede 的涅槃重生)开发文档中的一张图片。
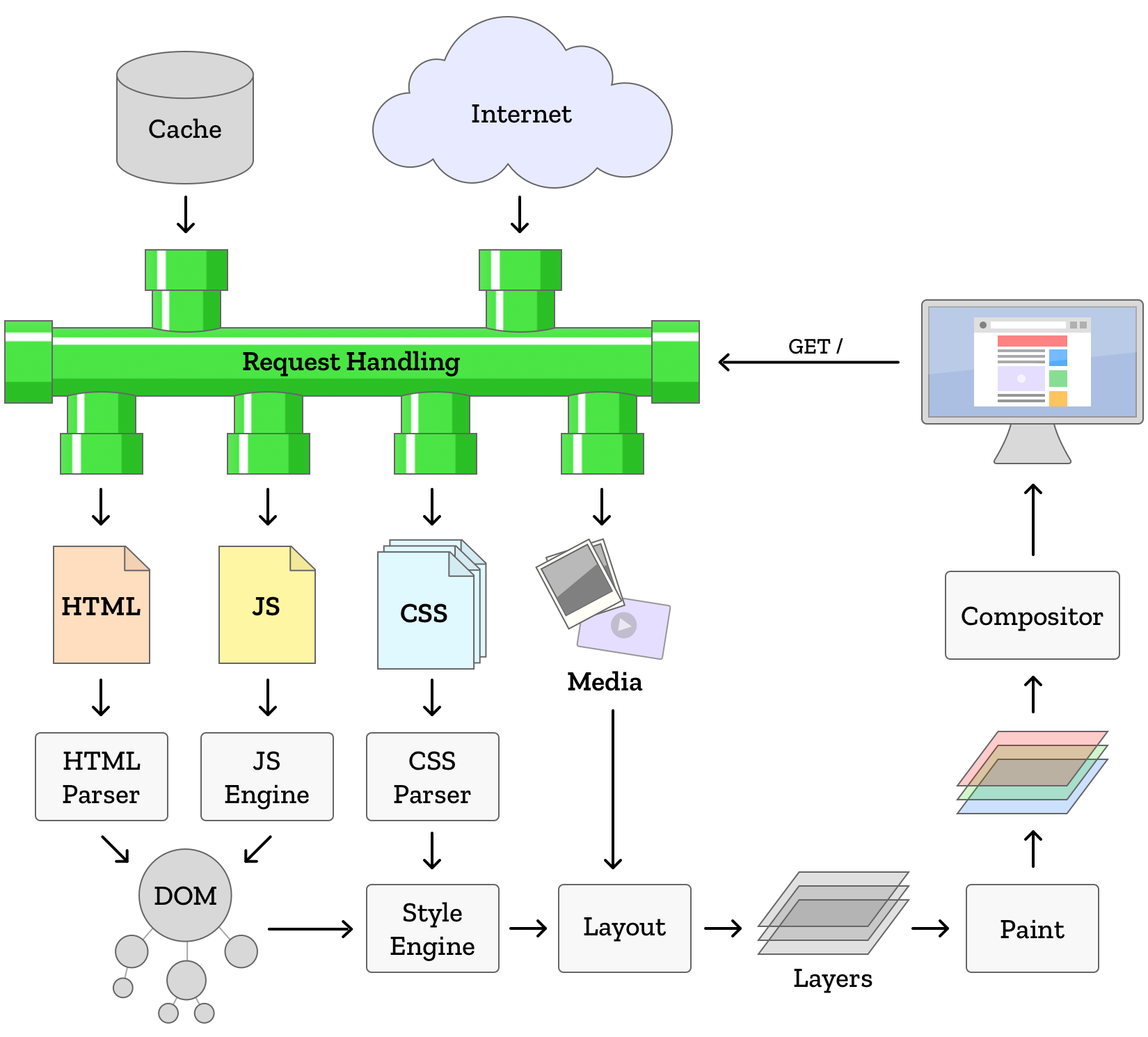
上面这张图片大体揭示了浏览器的渲染展示流程,但是从浏览器的整体架构上来说,上面的图片展示的也许只是浏览器体系中的冰山一角。
通常意义下,浏览器架构是如下图这样的:
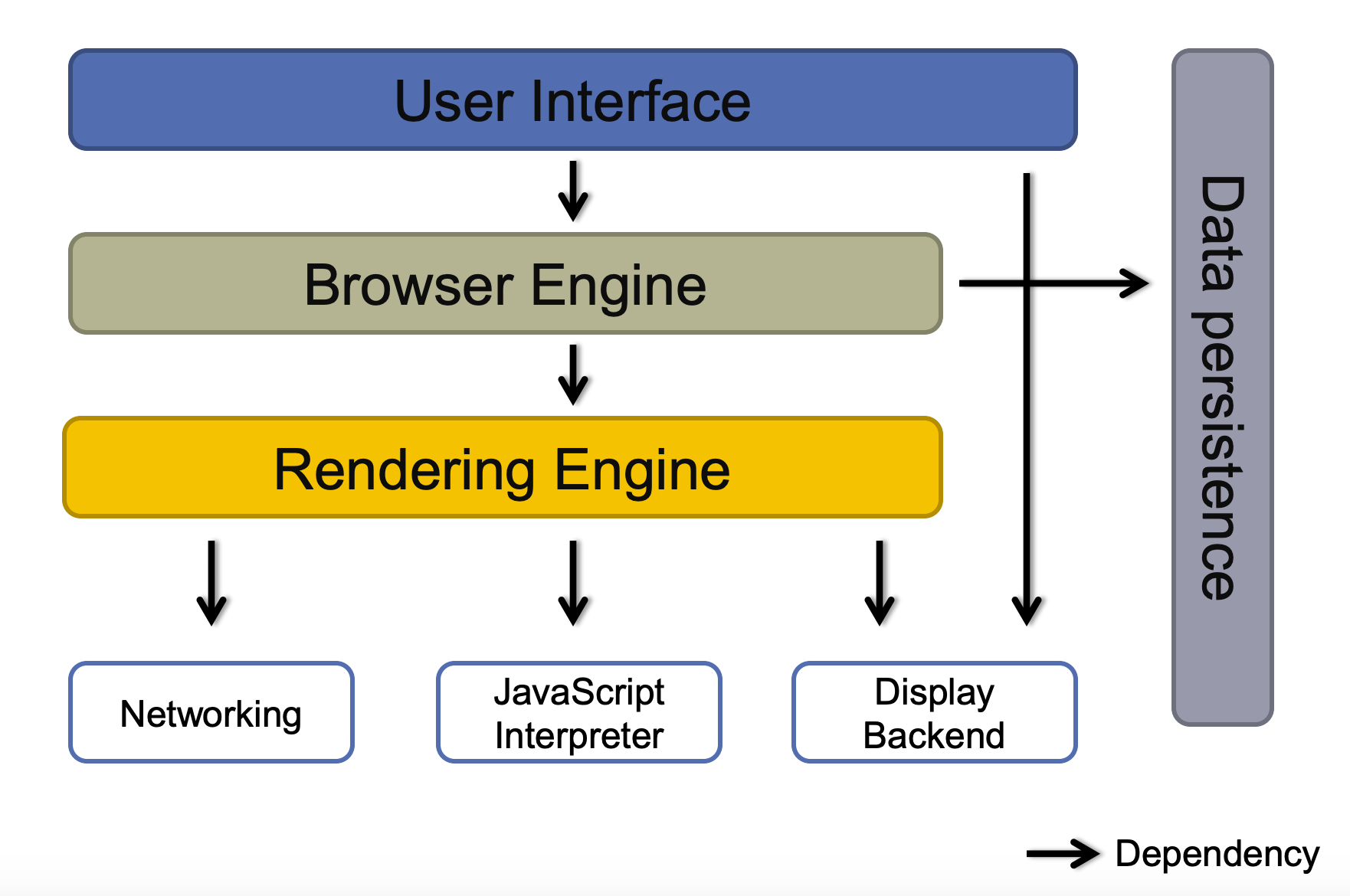
用户界面
包括地址栏、前进/后退按钮、书签菜单等。除了浏览器主窗口显示的您请求的页面外,其他显示的各个部分都属于用户界面。
浏览器引擎
用户界面和渲染引擎的桥梁,在用户界面和渲染引擎之间传送指令。浏览器引擎提供了开始加载 URL 资源 和一些其他高级操作方法,比如:重新加载、前进、后退动作,错误信息、加载进度等。
渲染引擎
负责显示请求的内容。如果请求的内容是 HTML,它就负责解析 HTML 和 CSS 内容,并将解析后的内容显示在屏幕上。
所谓浏览器内核就是指浏览器最重要或者说核心的部分”Rendering Engine”,译为”渲染引擎”。负责对网页语法的解析,比如 HTML、JavaScript,并渲染到网页上。所以浏览器内核也就是浏览器所采用的渲染引擎,渲染引擎决定这浏览器如何显示页面的内容和页面的格式信息。不同的浏览器内核对语法的解释也不相同,因此同一网页在不同内核的浏览器显示的效果也会有差异(浏览器兼容)。这也就是网页开发者在不需要同内核的浏览器中测试网页显示效果的原因。

延伸阅读:曾红极一时的红芯浏览器,官网对其介绍是:拥有智能的认证引擎、渲染引擎、管控引擎,而且还有强大的“国密通讯协议”,支持统一管控、远程控制。2018 年 8 月 15 日,红芯浏览器被爆出打开安装目录后出现大量和谷歌 Chrome 浏览器一致的同名文件,其安装程序的文件属性中也显示了原始文件名 chrome.exe,红芯浏览器的官网已撤下了浏览器的下载链接。8 月 16 日,红芯联合创始人高婧回应,红芯浏览器“包含‘Chrome’在里面”,但并非抄袭,而是“站在巨人的肩膀上去做创新”。

言归正传,浏览器内核主要包括以下三个技术分支:排版渲染引擎、 JavaScript 引擎,以及其他。
排版引擎:
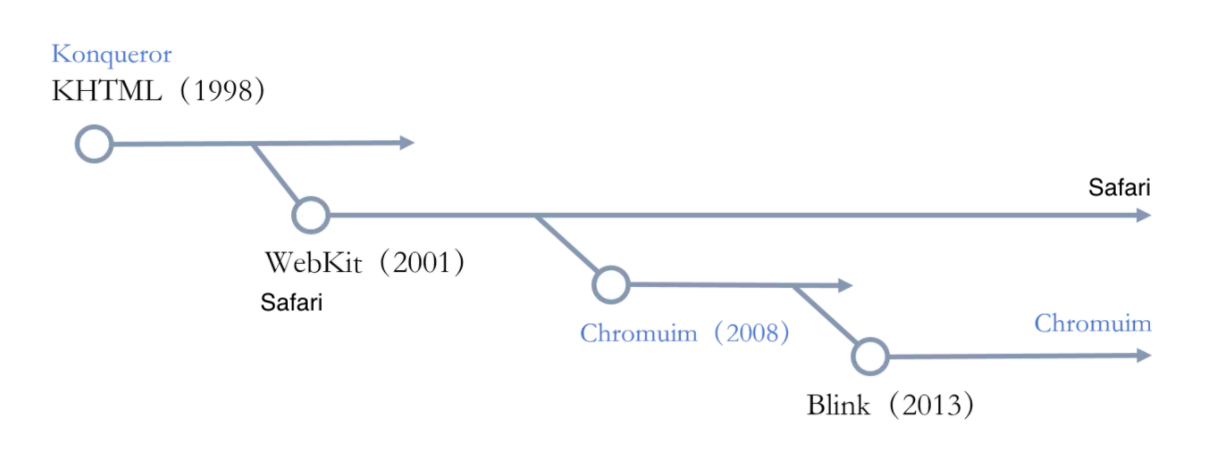
- KHTML:KHTML,是 HTML 网页排版引擎之一,由 KDE 所开发。KHTML 拥有速度快捷的优点,但对错误语法的容忍度则比 Mozilla 产品所使用的 Gecko 引擎小。苹果电脑于 2002 年采纳了 KHTML,作为开发 Safari 浏览器之用,并发布所修改的最新及过去版本源代码。后来发表的开源 WebCore 及 WebKit 引擎,它们均是 KHTML 的衍生产品。
- WebCore:WebCore 是苹果公司开发的排版引擎,它是在另外一个排版引擎“KHTML”的基础上而来的。使用 WebCore 的主要有 Safari 浏览器。
浏览器的内核引擎,基本上是四分天下:
- Trident: 又叫 MSHTML,是微软开发的一种排版引擎,IE 以 Trident 作为内核引擎;
- Gecko: Firefox 是基于 Gecko 开发;
- WebKit: 诞生于 1998 年,并于 2005 年由 Apple 公司开源,Safari, Google Chrome,傲游 3,猎豹浏览器,百度浏览器 opera 浏览器 基于 Webkit 开发。
- Presto: Opera 的内核,但由于市场选择问题,主要应用在手机平台–Opera mini。(2013 年 2 月 Opera 宣布转向 WebKit 引擎,2013 年 4 月 Opera 宣布放弃 WEBKIT,跟随 GOOGLE 的新开发的 blink 引擎。)
需要略作补充的是,我们经常还会听到 Chromium、Webkit2、Blink 这些引擎。
- Chromium:基于 webkit,08 年开始作为 Chrome 的引擎,Chromium 浏览器是 Chrome 的实验版,实验新特性。可以简单地理解为:Chromium 为实验版,具有众多新特性;Chrome 为稳定版。
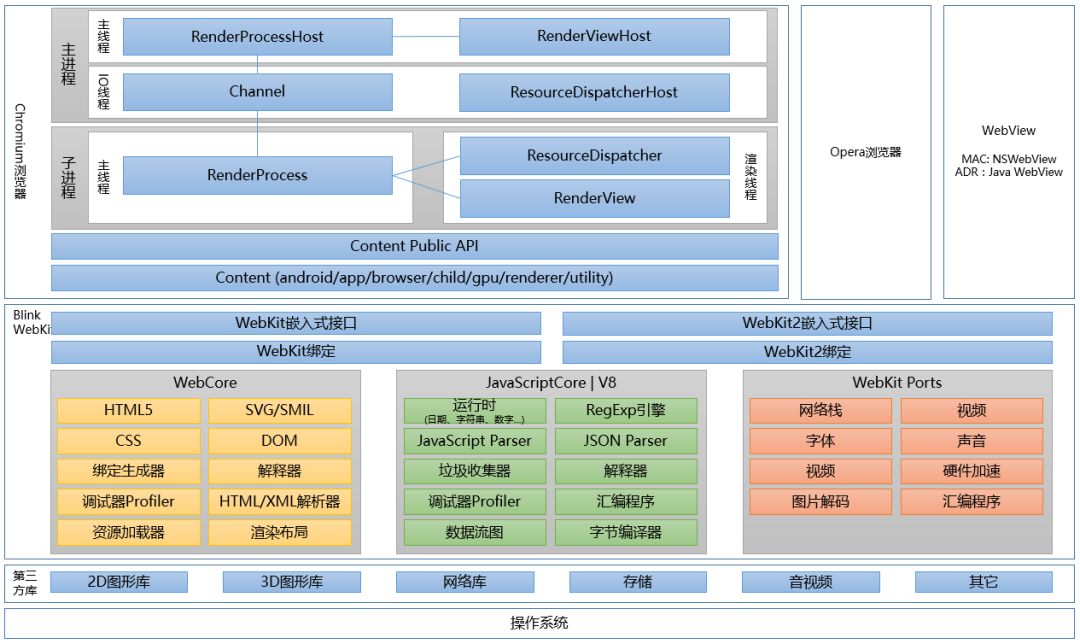
chromium 浏览器的架构,图片来源:万字详文:深入理解浏览器原理
- Webkit2:2010 年随 OS X Lion 一起面世。WebCore 层面实现进程隔离与 Google 的沙箱设计存在冲突。
- Blink:基于 Webkit2 分支,是 WebKit 中 WebCore 组件的一个分支,13 年谷歌开始作为 Chrome 28 的引擎集成在 Chromium 浏览器里。Android 的 WebView 同样基于 Webkit2,是现在对新特性支持度最好的内核。Opera(15 及往后版本)和 Yandex 浏览器中也在使用。
- 移动端基本上全部是 Webkit 或 Blink 内核(除去 Android 上腾讯家的 X5),这两个内核对新特性的支持度较高,所以新特性可以在移动端大展身手。
对浏览器的内核进行溯源的话,你会发现其实并没有那么多。 Google 的 Blink 来源于苹果开源的 Webkit,而 Webkit 来源于 KHTML, 属于 KDE(K 桌面环境,K Desktop Environment 的缩写) 的一部分, KDE 又是基于挪威公司 Trolltech 开发的 QT, 很多 KHTML 的贡献者其实也是来自于 Trolltech。
各内核关系图:
下面我们以 WebKit 为列,进行简单介绍,以便让你对渲染引擎有一个更多的理解。WebKit 由多个重要模块组成,通过下图我们可以对 WebKit 有个整体的了解:
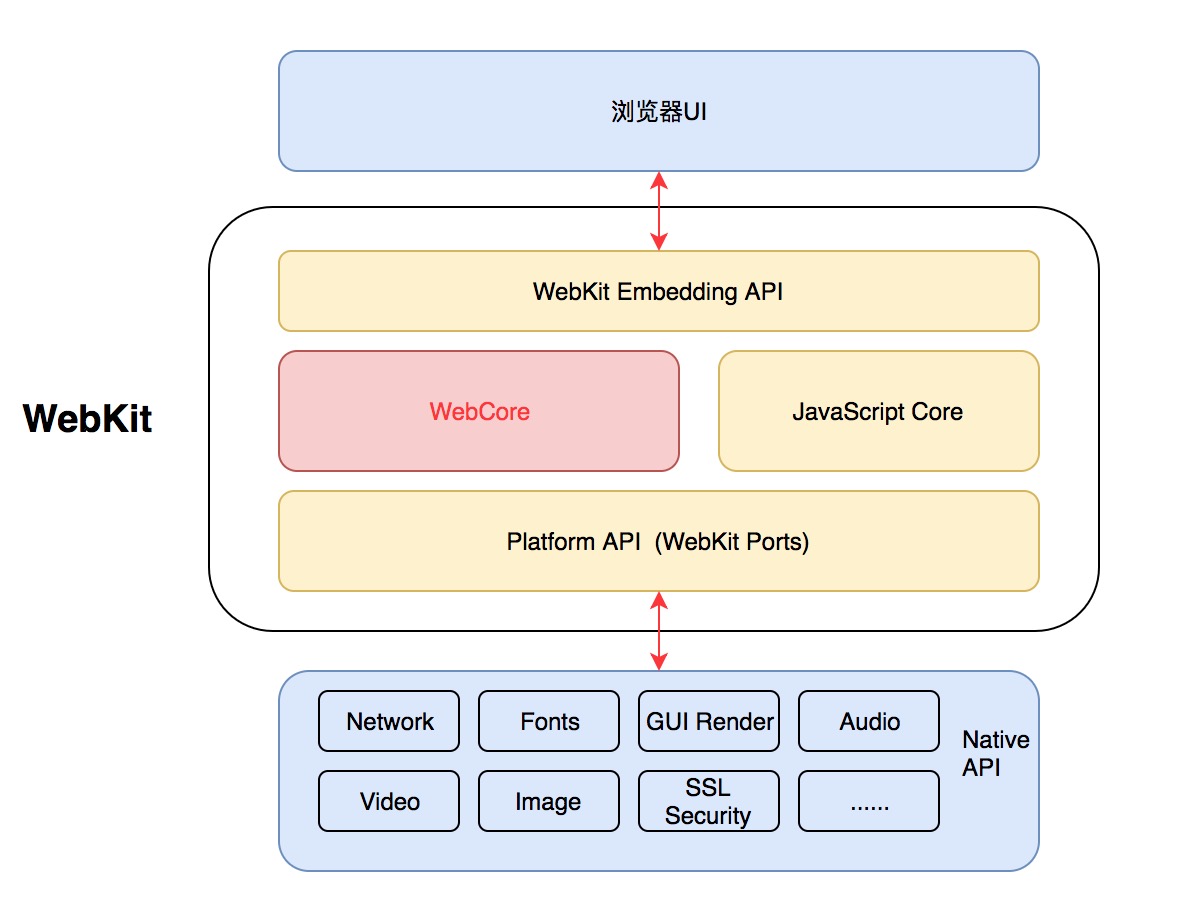
WebKit 就是一个页面渲染以及逻辑处理引擎,前端工程师把 HTML、JavaScript、CSS 这“三驾马车”作为输入,经过 WebKit 的处理,就输出成了我们能看到以及操作的 Web 页面。从上图我们可以看出来,WebKit 由图中框住的四个部分组成。而其中最主要的就是 WebCore 和 JSCore(或者是其它 JS 引擎)。除此之外,WebKit Embedding API 是负责浏览器 UI 与 WebKit 进行交互的部分,而 WebKit Ports 则是让 Webkit 更加方便的移植到各个操作系统、平台上,提供的一些调用 Native Library 的接口,比如在渲染层面,在 iOS 系统中,Safari 是交给 CoreGraphics 处理,而在 Android 系统中,Webkit 则是交给 Skia。
WebKit 的渲染流程:
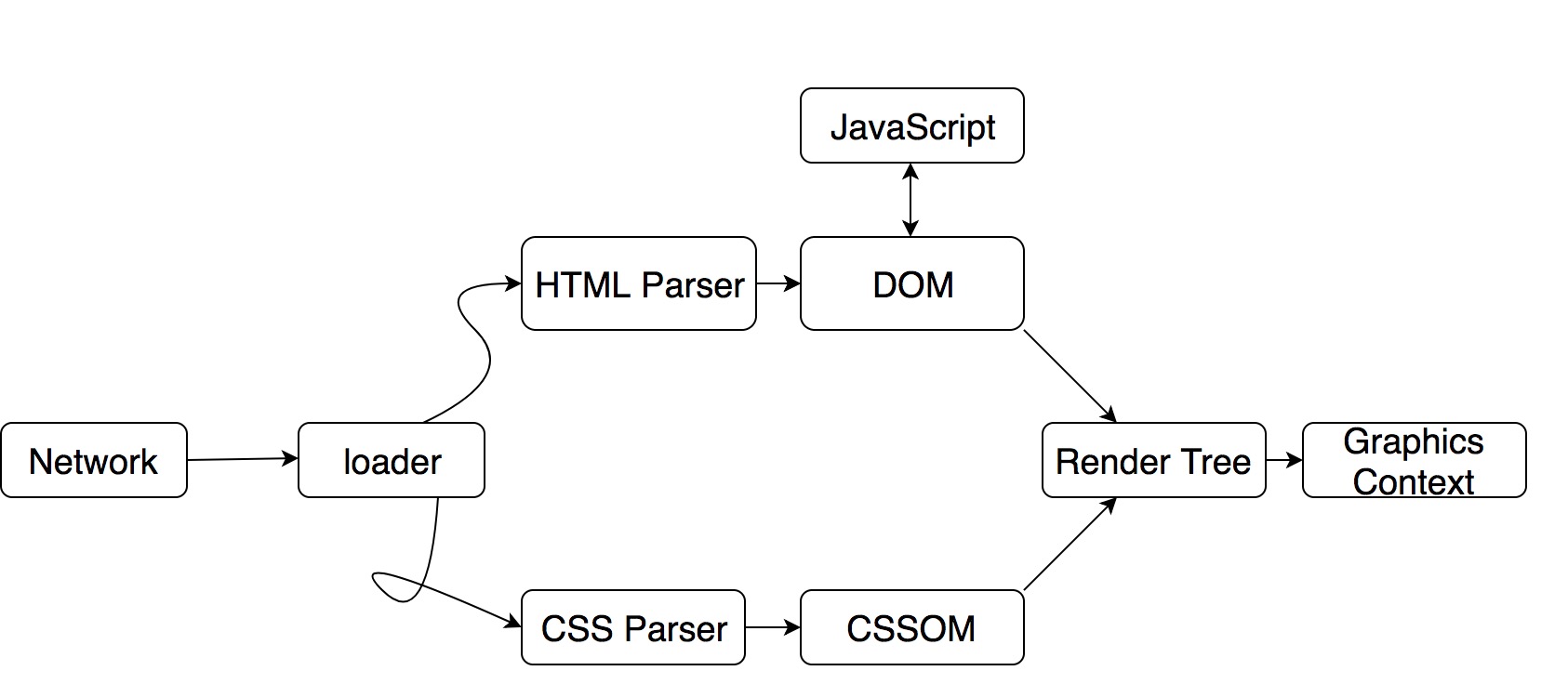
首先浏览器通过 URL 定位到了一堆由 HTML、CSS、JS 组成的资源文件,通过加载器把资源文件给 WebCore。之后 HTML Parser 会把 HTML 解析成 DOM 树,CSS Parser 会把 CSS 解析成 CSSOM 树。最后把这两棵树合并,生成最终需要的渲染树,再经过布局,与具体 WebKit Ports 的渲染接口,把渲染树渲染输出到屏幕上,成为了最终呈现在用户面前的 Web 页面。
网络
用于网络调用,比如 HTTP 请求。其接口与平台无关,并为所有平台提供底层实现,负责网络通信和安全。
JavaScript 解释器
用于解析和执行 JavaScript 代码,执行结果将传递给渲染引擎来展示。
用户界面后端
用于绘制基本的窗口小部件,比如组合框和窗口。其公开了与平台无关的通用接口,而在底层使用操作系统的用户界面方法。
数据存储
这是持久层,浏览器需要在硬盘上保存各种数据,例如 Cookie。新的 HTML 规范 (HTML5) 定义了“网络数据库”,这是一个完整而轻便的浏览器内数据库。
求同存异的浏览器架构
下面列出了部分浏览器的架构图,也许有些架构已经改变,有兴趣可以简单参考看看,除了 IE 之外,大体上各浏览器的整体架构都是类似的。
Mosaic 架构:
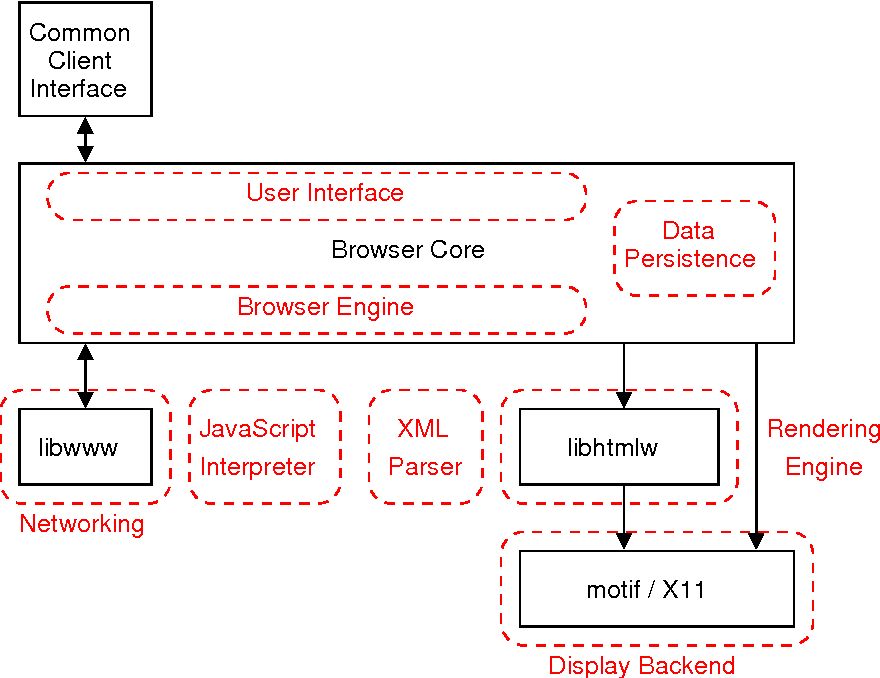
Firefox 架构:
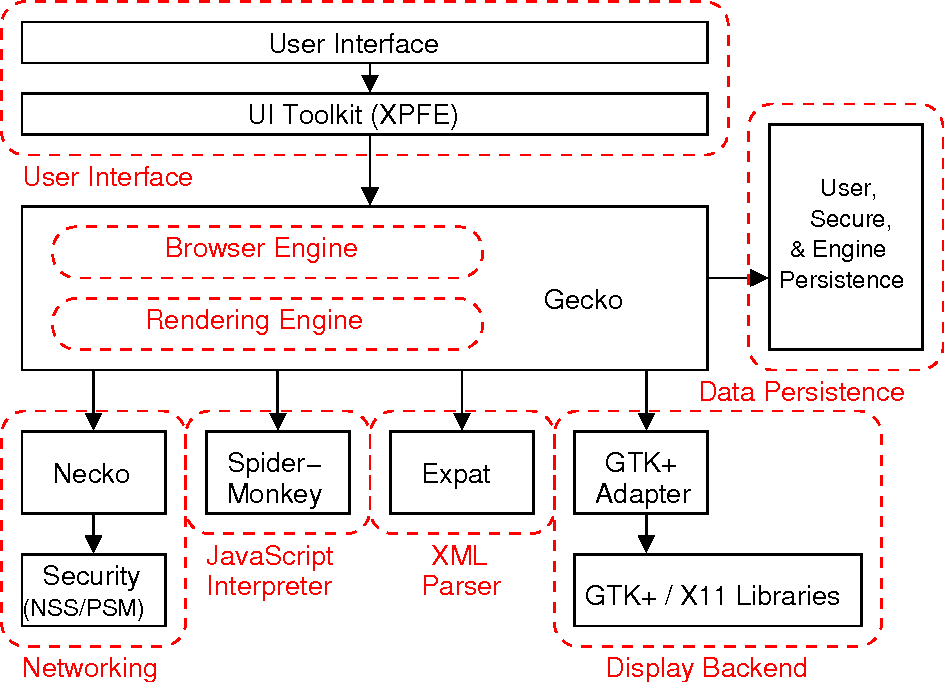
Chrome 架构:
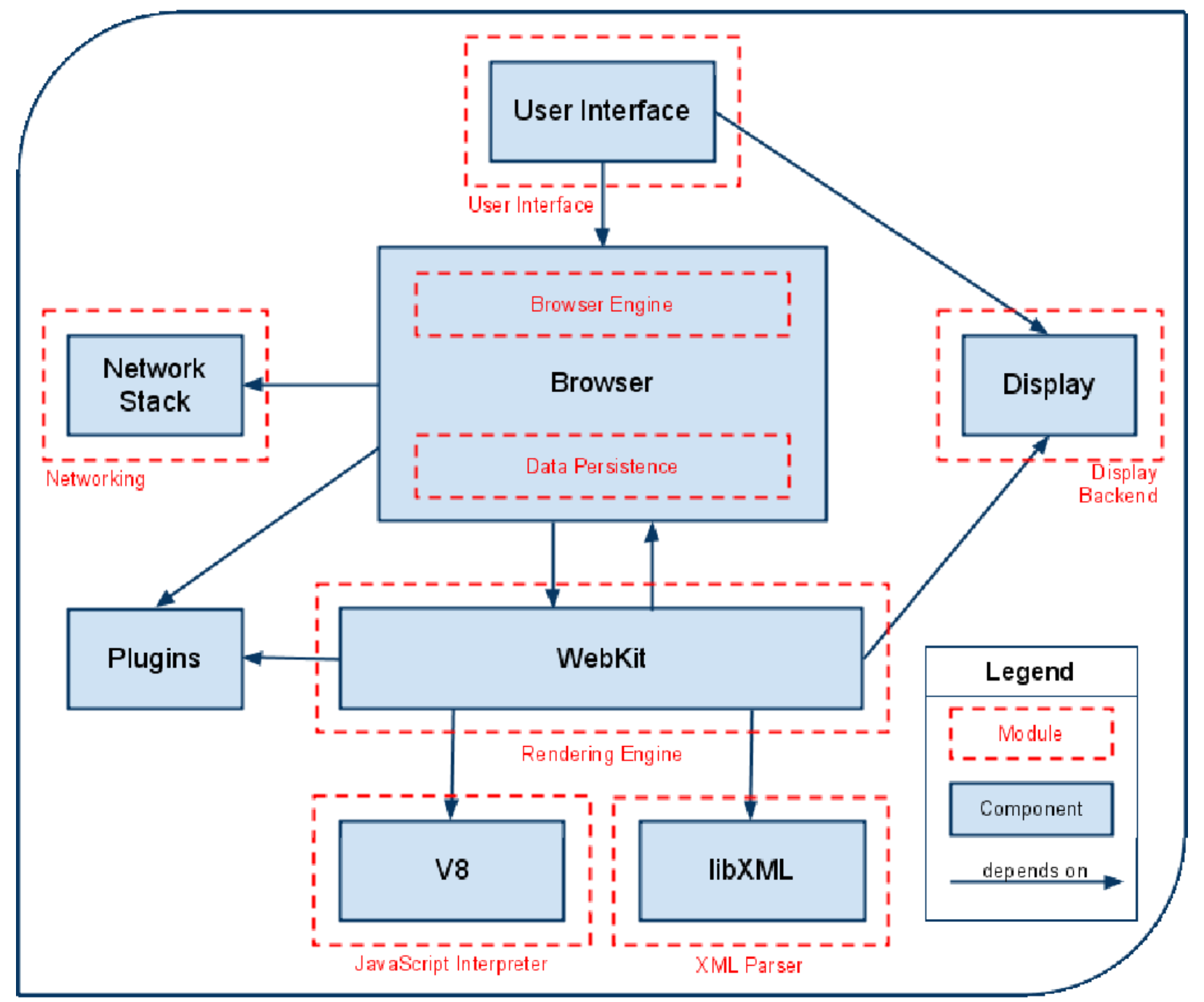
Safari 架构:
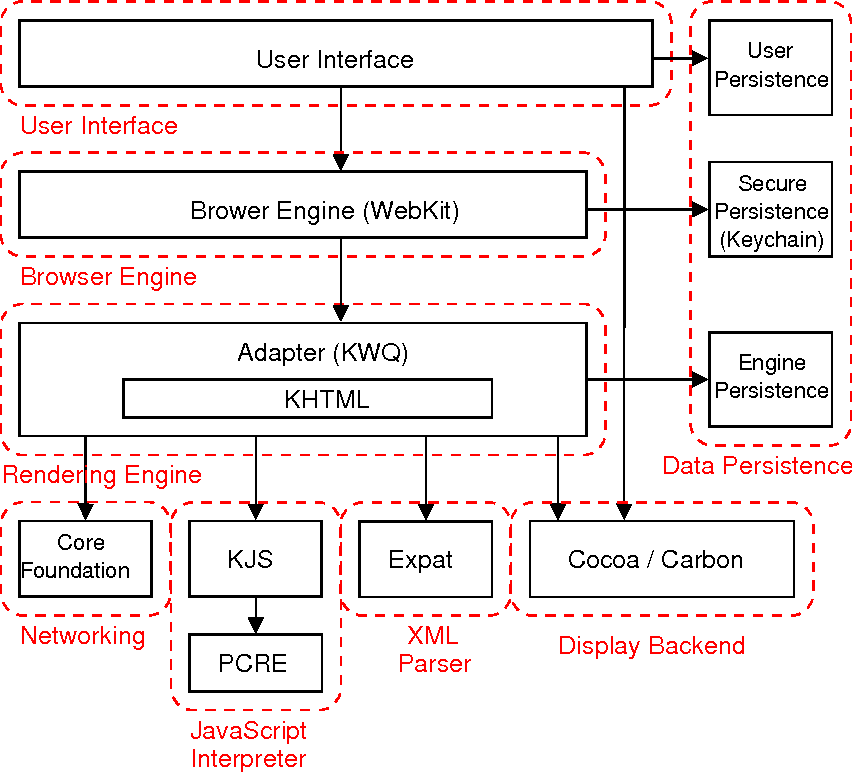
IE 架构:
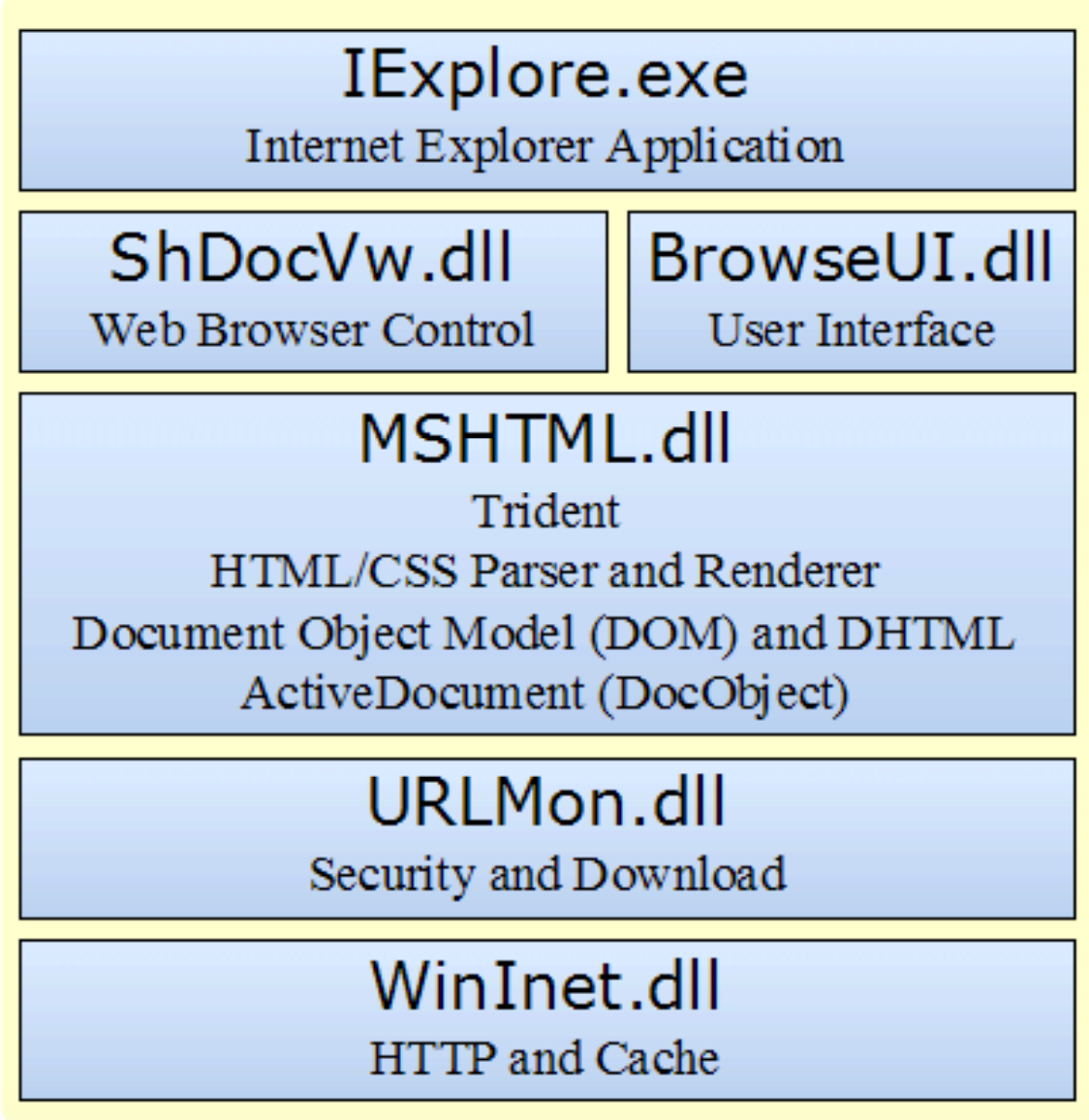
浏览器基本原理
Chrome V8
V8 一词最早见于“V-8 engine”,即 V8 发动机,一般使用在中高端车辆上。8 个气缸分成两组,每组 4 个,成 V 型排列。是高层次汽车运动中最常见的发动机结构,尤其在美国,IRL,ChampCar 和 NASCAR 都要求使用 V8 发动机。
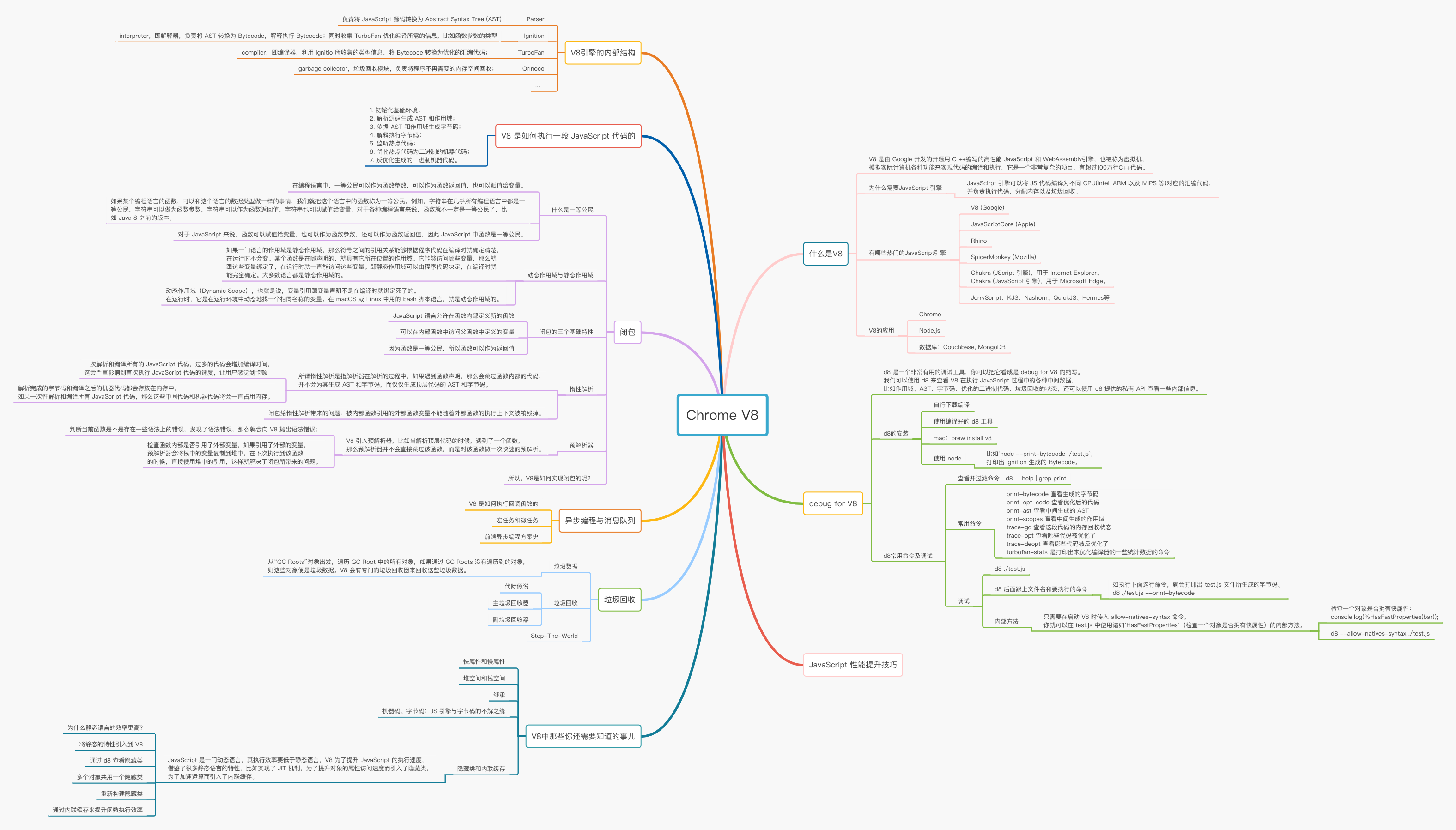
关于 Chrome V8,笔者曾有一篇笔记做了比较详细的介绍,全文脉络如下,感兴趣可以参考阅读。
V8 是依托 Chrome 发展起来的,后面确不局限于浏览器内核。发展至今 V8 应用于很多场景,例如流行的 nodejs,weex,快应用,早期的 RN。V8 曾经历过一次比较大的架构调整,主要变化在于“从字节码的放弃到真香”。
V8 的早期架构
V8 引擎诞生的使命就是要在速度和内存回收上进行革命。JavaScriptCore 的架构是采用生成字节码的方式,然后执行字节码。Google 觉得 JavaScriptCore 这套架构不行,生成字节码会浪费时间,不如直接生成机器码快。所以 V8 在前期的架构设计上是非常激进的,采用了直接编译成机器码的方式。后期的实践证明 Google 的这套架构速度是有改善,但是同时也造成了内存消耗问题。
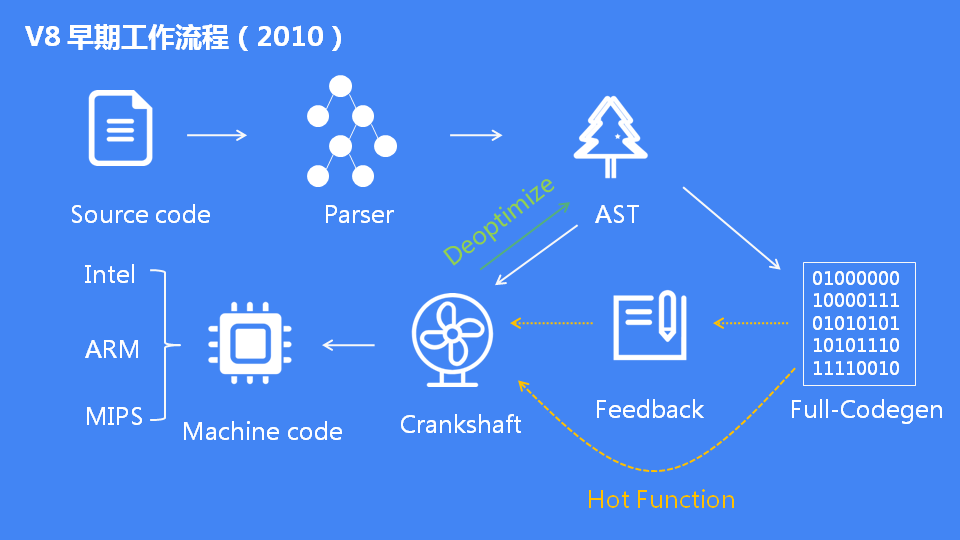
早期的 V8 有 Full-Codegen 和 Crankshaft 两个编译器。V8 首先用 Full-Codegen 把所有的代码都编译一次,生成对应的机器码。JS 在执行的过程中,V8 内置的 Profiler 筛选出热点函数并且记录参数的反馈类型,然后交给 Crankshaft 来进行优化。所以 Full-Codegen 本质上是生成的是未优化的机器码,而 Crankshaft 生成的是优化过的机器码。
随着网页的复杂化,V8 也渐渐的暴露出了自己架构上的缺陷:
- Full-Codegen 编译直接生成机器码,导致内存占用大;
- Full-Codegen 编译直接生成机器码,导致编译时间长,导致启动速度慢;
- Crankshaft 无法优化 try,catch 和 finally 等关键字划分的代码块;
- Crankshaft 新加语法支持,需要为此编写适配不同的 Cpu 架构代码。
V8 的现有架构
为了解决上述缺点,V8 借鉴 JavaScriptCore 的架构,生成字节码。V8 采用生成字节码的方式后,整体流程如下图:
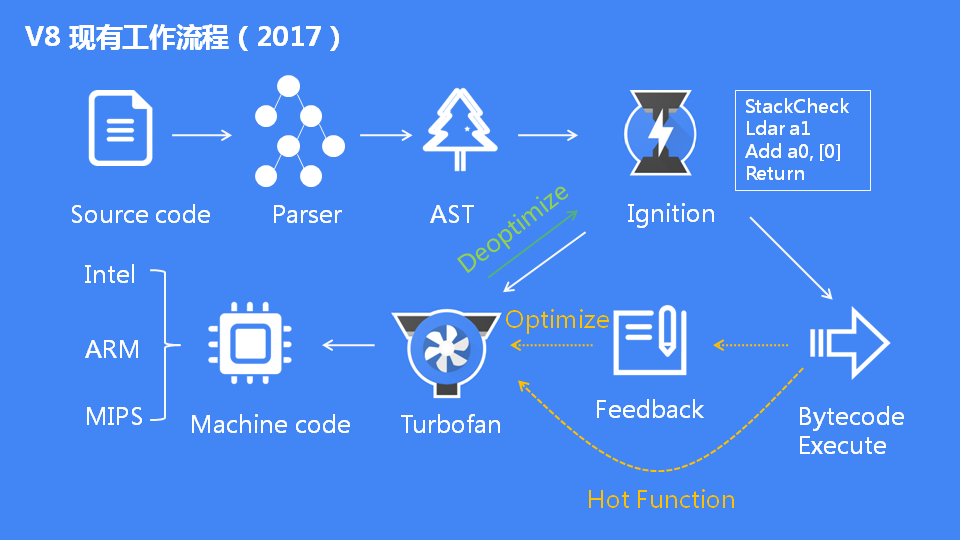
现在的 V8 是一个非常复杂的项目,有超过 100 万行 C++代码。它由许多子模块构成,其中这 4 个模块是最重要的:
-
Parser:负责将 JavaScript 源码转换为 Abstract Syntax Tree (AST)
确切的说,在“Parser”将 JavaScript 源码转换为 AST 前,还有一个叫”Scanner“的过程,具体流程如下:
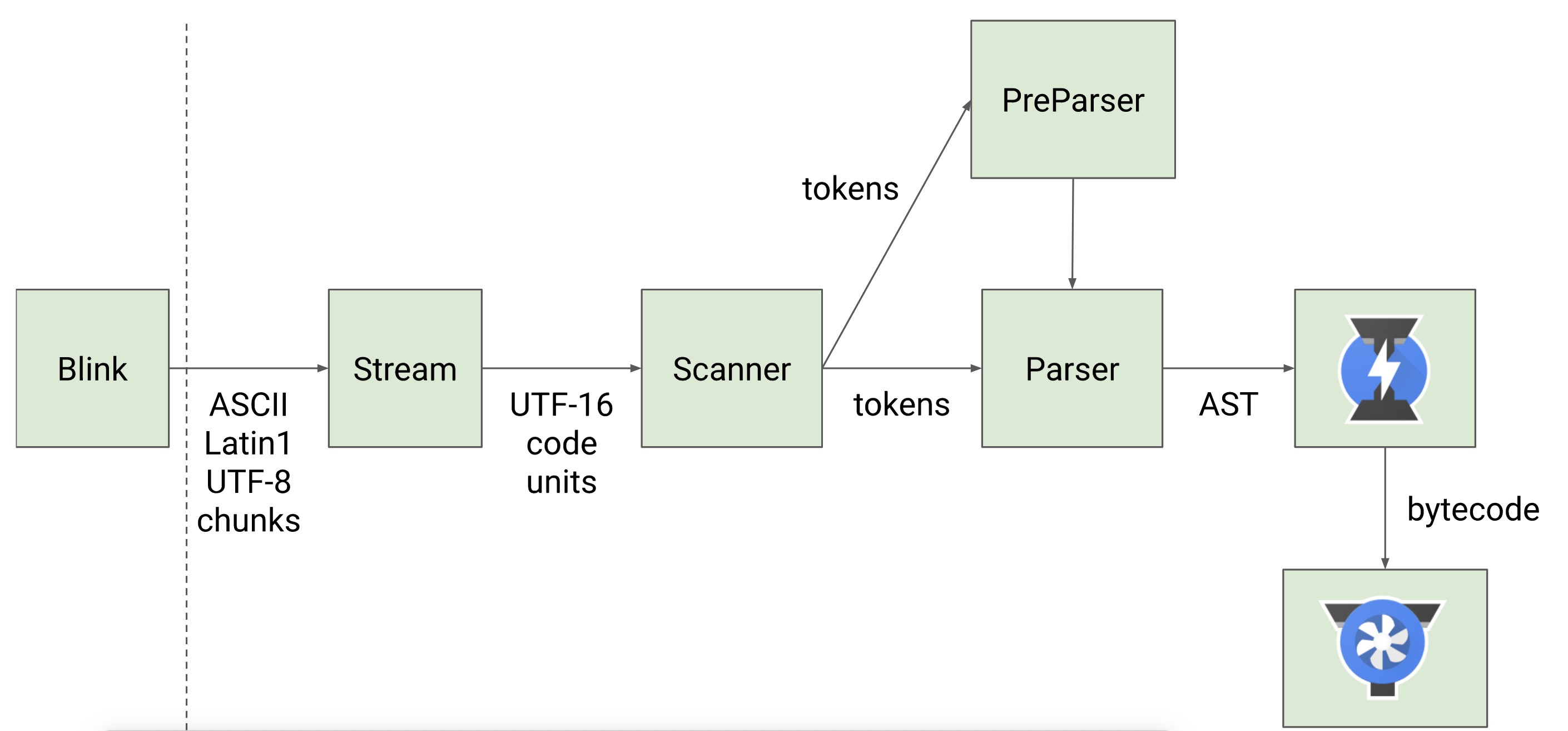
-
Ignition:interpreter,即解释器,负责将 AST 转换为 Bytecode,解释执行 Bytecode;同时收集 TurboFan 优化编译所需的信息,比如函数参数的类型;解释器执行时主要有四个模块,内存中的字节码、寄存器、栈、堆。Ignition 的原始动机是减少移动设备上的内存消耗。在 Ignition 之前,V8 的 Full-codegen 基线编译器生成的代码通常占据 Chrome 整体 JavaScript 堆的近三分之一。这为 Web 应用程序的实际数据留下了更少的空间。Ignition 的字节码可以直接用 TurboFan 生成优化的机器代码,而不必像 Crankshaft 那样从源代码重新编译。Ignition 的字节码在 V8 中提供了更清晰且更不容易出错的基线执行模型,简化了去优化机制,这是 V8 自适应优化的关键特性。最后,由于生成字节码比生成 Full-codegen 的基线编译代码更快,因此激活 Ignition 通常会改善脚本启动时间,从而改善网页加载。
-
TurboFan:compiler,即优化编译器,利用 Ignition 所收集的类型信息,将 Bytecode 转换为优化的汇编代码;TurboFan 项目最初于 2013 年底启动,旨在解决 Crankshaft 的缺点。Crankshaft 只能优化 JavaScript 语言的子集。例如,它不是设计用于使用结构化异常处理优化 JavaScript 代码,即由 JavaScript 的 try,catch 和 finally 关键字划分的代码块。很难在 Crankshaft 中添加对新语言功能的支持,因为这些功能几乎总是需要为九个支持的平台编写特定于体系结构的代码。
-
Orinoco:garbage collector,垃圾回收模块,负责将程序不再需要的内存空间回收。
采用新的 Ignition+TurboFan 架构后,比 Full-codegen+Crankshaft 架构内存降低一半多,且 70%左右的网页速度得到了提升。
在运行 C、C++以及 Java 等程序之前,需要进行编译,不能直接执行源码;但对于 JavaScript 来说,我们可以直接执行源码(比如:node test.js),它是在运行的时候先编译再执行,这种方式被称为即时编译(Just-in-time compilation),简称为 JIT。因此,V8 也属于 JIT 编译器。
JavaScriptCore
V8 未诞生之前,早期主流的 JavaScript 引擎是 JavaScriptCore 引擎。JavaScriptCore(以下简称 JSCore)主要服务于 Webkit 浏览器内核,他们都是由苹果公司开发并开源出来。JSCore 是 WebKit 默认内嵌的 JS 引擎,之所以说是默认内嵌,是因为很多基于 WebKit 分支开发的浏览器引擎都开发了自家的 JS 引擎,其中最出名的就是前文提到的 Chrome 的 V8。这些JS 引擎的使命都是解释执行 JS 脚本。而在渲染流程上,JS 和 DOM 树之间存在着互相关联,这是因为浏览器中的 JS 脚本最主要的功能就是操作 DOM 树,并与之交互。我们可以通过下图看下它的工作流程:
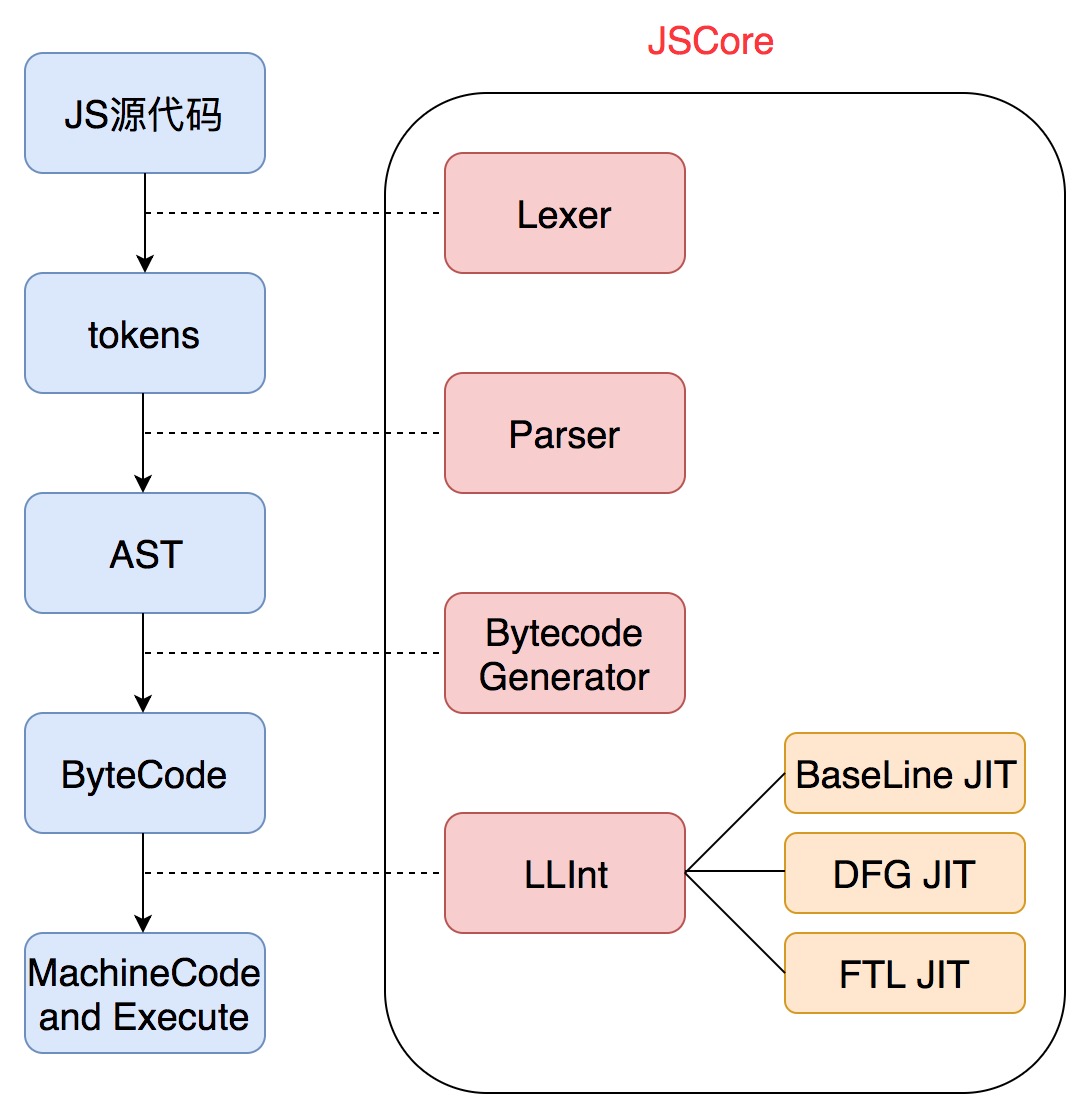
JavaScriptCore 主要模块:Lexer 词法分析器,将脚本源码分解成一系列的 Token;Parser 语法分析器,处理 Token 并生成相应的语法树;LLInt 低级解释器,执行 Parser 生成的二进制代码;Baseline JIT 基线 JIT(just in time 实时编译);DFG 低延迟优化的 JIT;FTL 高通量优化的 JIT。
可以看到,相比静态编译语言生成语法树之后,还需要进行链接,装载生成可执行文件等操作,解释型语言在流程上要简化很多。这张流程图右边画框的部分就是 JSCore 的组成部分:Lexer(词法分析)、Parser(语法分析)、LLInt 以及 JIT(解释执行)的部分(之所以 JIT 的部分是用橙色标注,是因为并不是所有的 JSCore 中都有 JIT 部分)。
- 词法分析很好理解,就是把一段我们写的源代码分解成 Token 序列的过程,这一过程也叫分词。在 JSCore,词法分析是由 Lexer 来完成(有的编译器或者解释器把分词叫做 Scanner,比如 Chrome v8)。
- 跟人类语言一样,我们讲话的时候其实是按照约定俗成,交流习惯按照一定的语法讲出一个又一个词语。那类比到计算机语言,计算机要理解一门计算机语言,也要理解一个语句的语法。Parser 会把 Lexer 分析之后生成的 token 序列进行语法分析,并生成对应的一棵抽象语法树(AST)。之后,ByteCodeGenerator 会根据 AST 来生成 JSCore 的字节码,完成整个语法解析步骤。
- JS 源代码经过了词法分析和语法分析这两个步骤,转成了字节码,其实就是经过任何一门程序语言必经的步骤–编译。但是不同于我们编译运行 OC 代码,JS 编译结束之后,并不会生成存放在内存或者硬盘之中的目标代码或可执行文件。生成的指令字节码,会被立即被 JSCore 这台虚拟机进行逐行解释执行。运行指令字节码(ByteCode)是 JS 引擎中很核心的部分,各家 JS 引擎的优化也主要集中于此。
PS:严格的讲,语言本身并不存在编译型或者是解释型,因为语言只是一些抽象的定义与约束,并不要求具体的实现,执行方式。这里讲 JS 是一门“解释型语言”只是 JS 一般是被 JS 引擎动态解释执行,而并不是语言本身的属性。
如果对 JavaScriptCore 有更多兴趣,关于 JavaScriptCore 的更多细节,建议延伸阅读以下几篇博文:
浏览器与 JavaScript
这一小结,还是以 Chrome V8 为例,简单阐述浏览器与 JavaScript 的关系。
在 V8 出现之前,所有的 JavaScript 虚拟机所采用的都是解释执行的方式,这是 JavaScript 执行速度过慢的一个主要原因。而 V8 率先引入了即时编译(JIT)的双轮驱动的设计(混合使用编译器和解释器的技术),这是一种权衡策略,混合编译执行和解释执行这两种手段,给 JavaScript 的执行速度带来了极大的提升。V8 出现之后,各大厂商也都在自己的 JavaScript 虚拟机中引入了 JIT 机制,所以目前市面上 JavaScript 虚拟机都有着类似的架构。另外,V8 也是早于其他虚拟机引入了惰性编译、内联缓存、隐藏类等机制,进一步优化了 JavaScript 代码的编译执行效率。
V8 执行一段 JavaScript 的流程
V8 执行一段 JavaScript 的流程如下图所示:
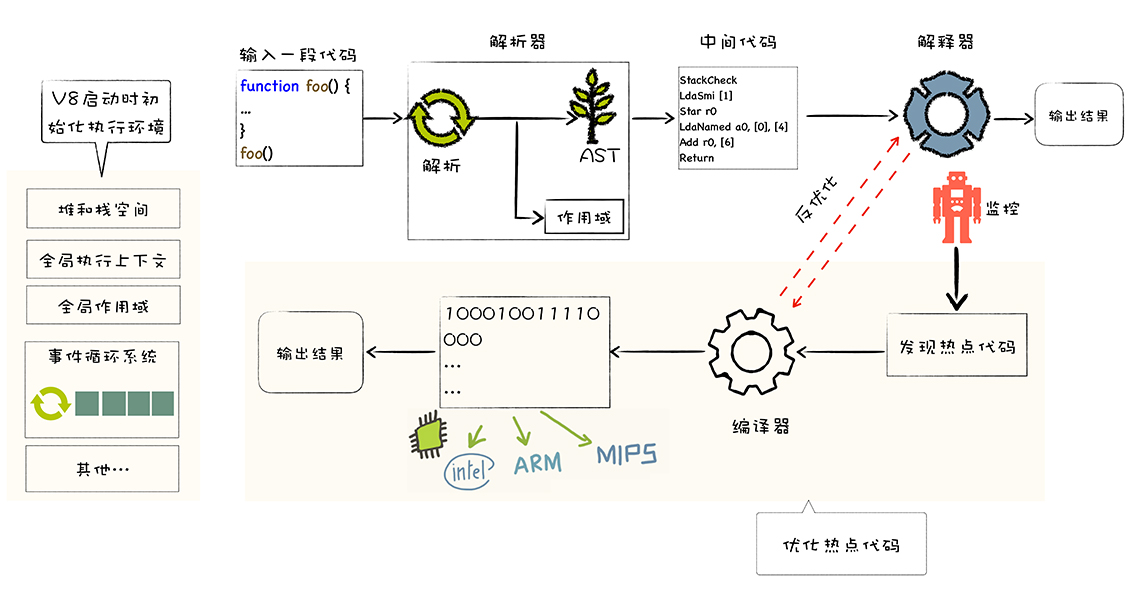
结合上文介绍的 Chrome V8 架构,聚焦到 JavaScript 上,浏览器拿到 JavaScript 源码,Parser,Ignition 以及 TurboFan 可以将 JS 源码编译为汇编代码,其流程图如下:
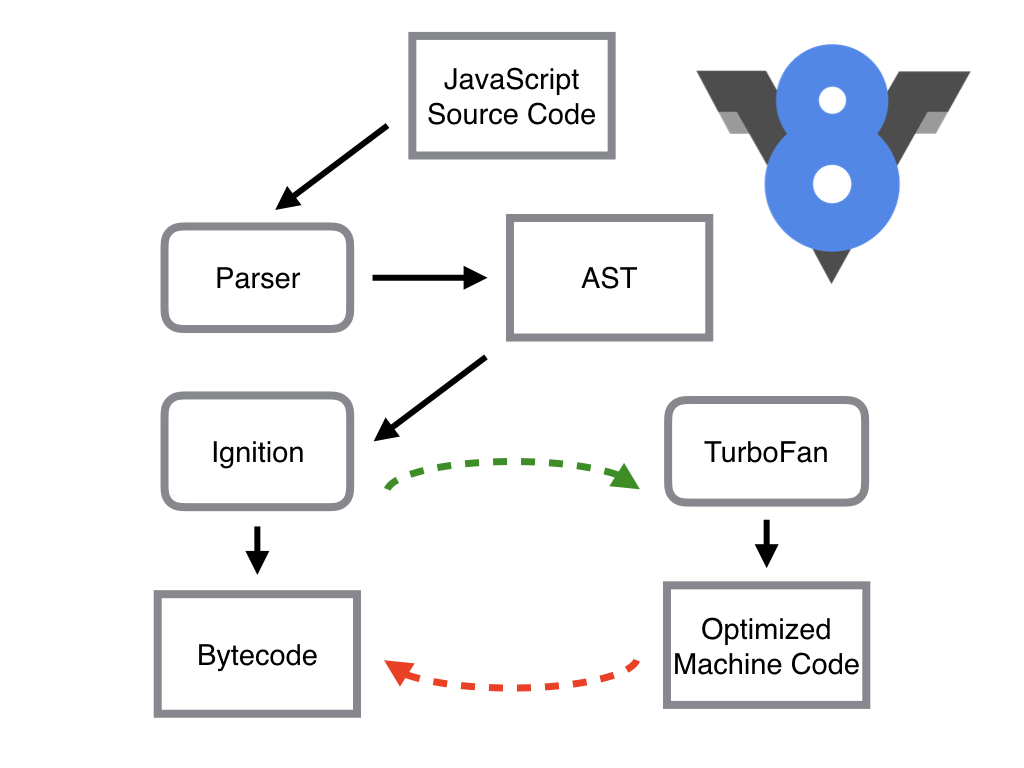
简单地说,Parser 将 JS 源码转换为 AST,然后 Ignition 将 AST 转换为 Bytecode,最后 TurboFan 将 Bytecode 转换为经过优化的 Machine Code(实际上是汇编代码)。
- 如果函数没有被调用,则 V8 不会去编译它。
- 如果函数只被调用 1 次,则 Ignition 将其编译 Bytecode 就直接解释执行了。TurboFan 不会进行优化编译,因为它需要 Ignition 收集函数执行时的类型信息。这就要求函数至少需要执行 1 次,TurboFan 才有可能进行优化编译。
- 如果函数被调用多次,则它有可能会被识别为热点函数,且 Ignition 收集的类型信息证明可以进行优化编译的话,这时 TurboFan 则会将 Bytecode 编译为 Optimized Machine Code(已优化的机器码),以提高代码的执行性能。
图片中的红色虚线是逆向的,也就是说 Optimized Machine Code 会被还原为 Bytecode,这个过程叫做 Deoptimization。这是因为 Ignition 收集的信息可能是错误的,比如 add 函数的参数之前是整数,后来又变成了字符串。生成的 Optimized Machine Code 已经假定 add 函数的参数是整数,那当然是错误的,于是需要进行 Deoptimization。
function add(x, y) {
return x + y;
}
add(1, 2);
add('1', '2');
V8 本质上是一个虚拟机,因为计算机只能识别二进制指令,所以要让计算机执行一段高级语言通常有两种手段:
- 第一种是将高级代码转换为二进制代码,再让计算机去执行;
- 另外一种方式是在计算机安装一个解释器,并由解释器来解释执行。
- 解释执行和编译执行都有各自的优缺点,解释执行启动速度快,但是执行时速度慢,而编译执行启动速度慢,但是执行速度快。为了充分地利用解释执行和编译执行的优点,规避其缺点,V8 采用了一种权衡策略,在启动过程中采用了解释执行的策略,但是如果某段代码的执行频率超过一个值,那么 V8 就会采用优化编译器将其编译成执行效率更加高效的机器代码。
简单总结如下,V8 执行一段 JavaScript 代码所经历的主要流程包括:
- 初始化基础环境;
- 解析源码生成 AST 和作用域;
- 依据 AST 和作用域生成字节码;
- 解释执行字节码;
- 监听热点代码;
- 优化热点代码为二进制的机器代码;
- 反优化生成的二进制机器代码。
Chrome V8 的事件机制
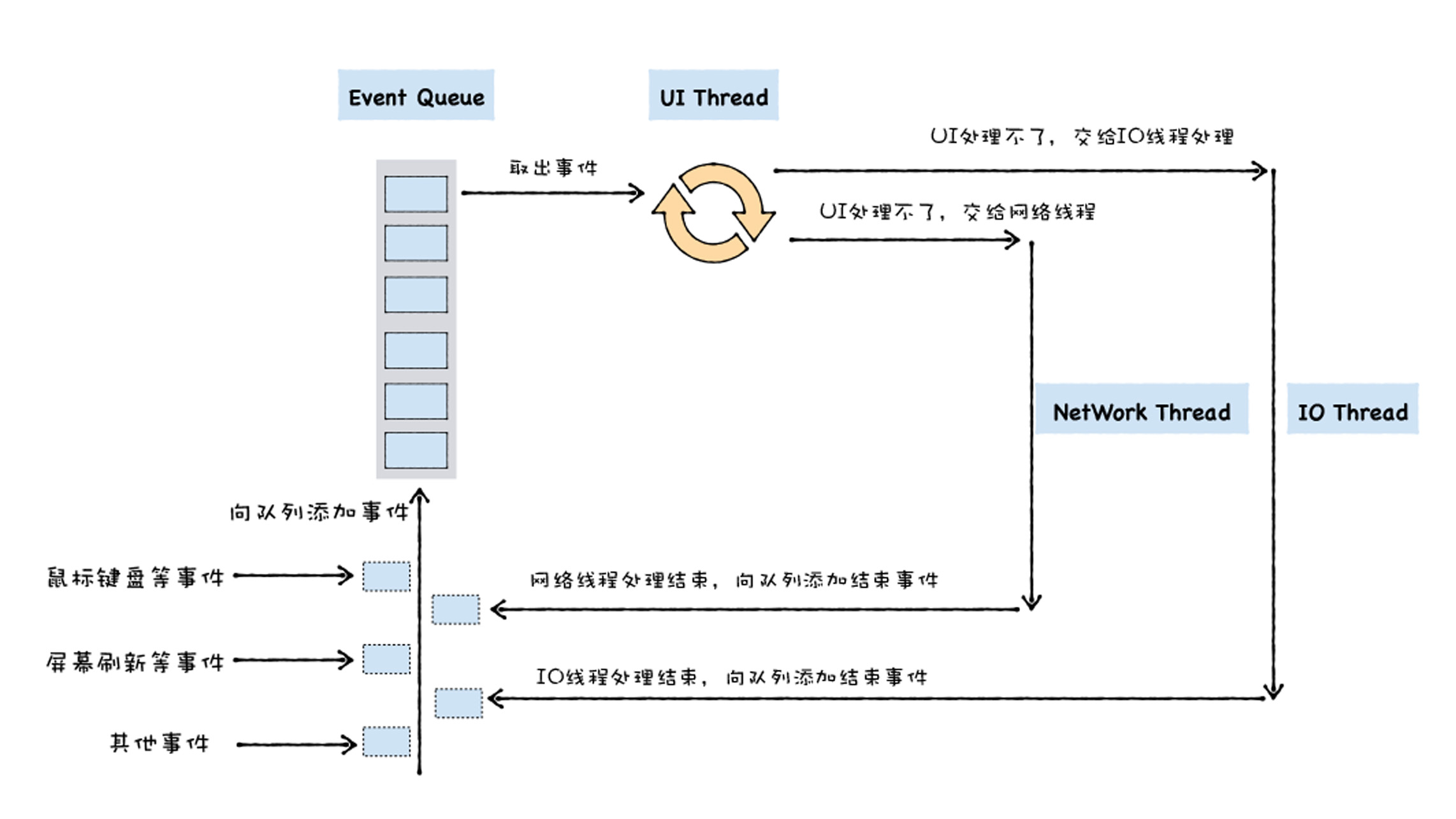
关于异步编程和消息队列,UI 线程提供一个消息队列,并将待执行的事件添加到消息队列中,然后 UI 线程会不断循环地从消息队列中取出事件、执行事件,通用 UI 线程宏观架构如下图所示:
浏览器的不同形态
WebView
WebView 是一种嵌入式浏览器,原生应用可以用它来展示网络内容。WebView 只是一个可视化的组件/控件/微件等。这样我们可以用它来作为我们原生 app 的视觉部分。当你使用原生应用时,WebView 可能只是被隐藏在普通的原生 UI 元素中,你甚至用不到注意到它。
如果你把浏览器想象成两部分,一部分是 UI(地址栏,导航栏按钮等),其它部分是把标记跟代码转换成我们可见和可交互视图的引擎。WebView 就是浏览器引擎部分,你可以像插入 iframe 一样将 Webview 插入到你的原生应用中,并且编程化的告诉它将会加载什么网页内容。
运行在你的 WebView 中的 JavaScript 有能力调用原生的系统 API。这意味着你不必受到 Web 代码通常必须遵守的传统浏览器安全沙箱的限制。下图解释了使用这种技术后的架构差异:
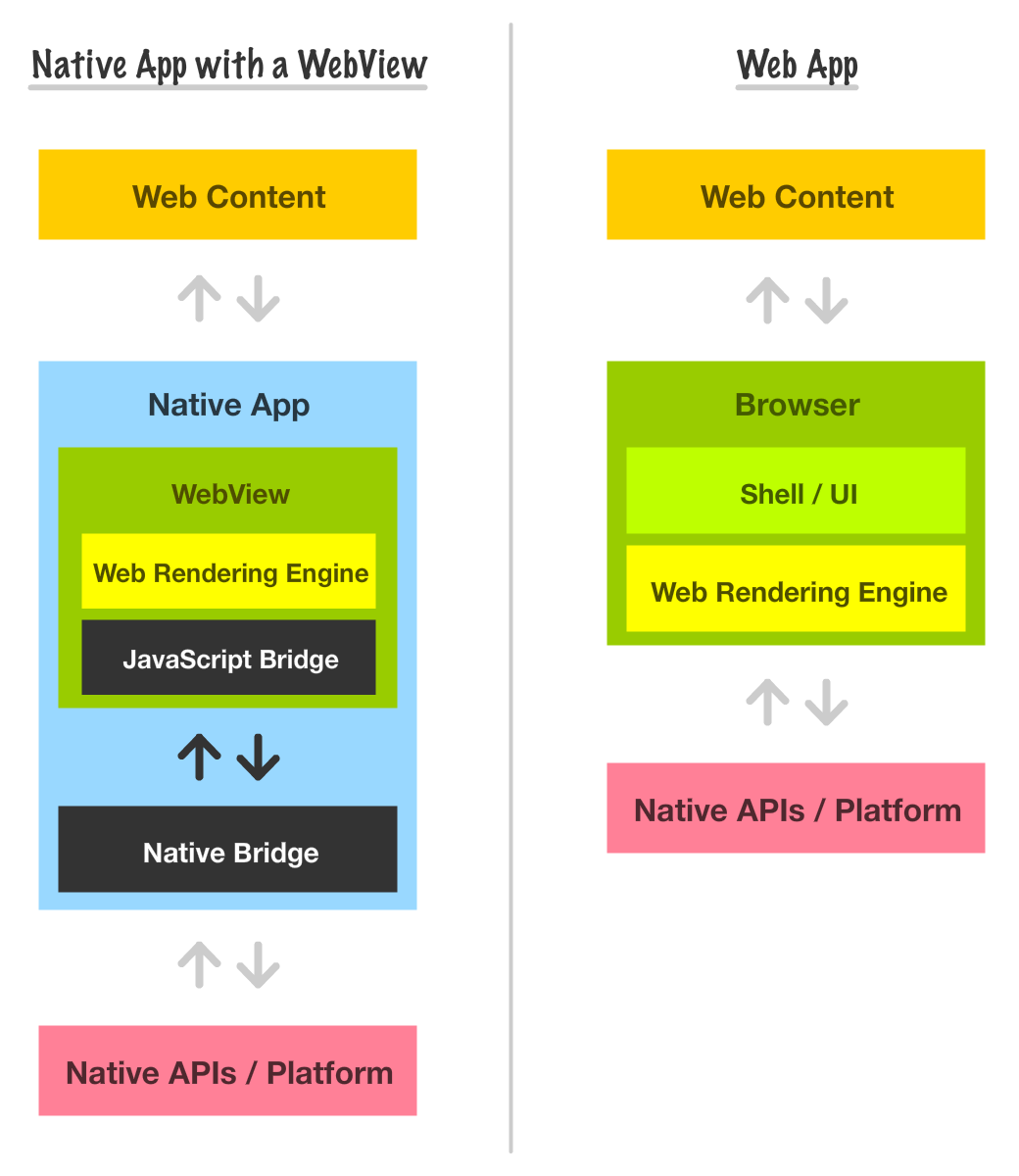
默认情况下,在 WebView 或 Web 浏览器中运行的任何 Web 代码都与应用的其余部分保持隔离。这样做是出于安全原因,主要是为降低恶意的 JavaScript 代码对系统造成的伤害。对于任意 Web 内容,这种安全级别很有意义,因为你永远不能完全信任加载的 Web 内容。但 WebView 的情况并非如此,对于 WebView 方案,开发人员通常可以完全控制加载的内容。恶意代码进入并在设备上造成混乱的可能性非常低。
这就是为什么对于 WebView,开发人员可以使用各种受支持的方式来覆盖默认的安全行为,并让 Web 代码和原生应用代码相互通信。这种沟通通常称为 bridge。你可以在上文的图片中看到 bridge 可视化为 Native Bridge 和 JavaScript Bridge 的一部分。
WebView 非常好,虽然它看起来像是完全特殊和独特的,但请记住,它们只不过是一个在应用中设置好位置和大小的、没有任何花哨 UI 的浏览器,这就是它的精髓。大多数情况下,除非您调用原生 API,否则您不必在 WebView 中专门测试您的 Web 应用程序。此外,您在 WebView 中看到的内容与您在浏览器中看到的内容相同,尤其是使用同一渲染引擎时:
- 在 iOS 上,Web 渲染引擎始终是 WebKit,与 Safari 和 Chrome 相同。是的,你没看错。iOS 上的 Chrome 实际上使用了 WebKit。
- 在 Android 上的渲染引擎通常是 Blink,与 Chrome 相同。
- 在 Windows,Linux 和 macOS 上,由于这些是更宽松的桌面平台,因此在选择 WebView 风格和渲染引擎时会有很大的灵活性。你看到的流行渲染引擎将是 Blink(Chrome)和 Trident(Internet Explorer),但是没有一个引擎可以依赖。这完全取决于应用以及它正在使用的 WebView 引擎。
WebView 的应用:
- WebView 最常见的用途之一是显示链接的内容;
- 广告仍然是原生应用最流行的赚钱方式之一,大多数广告是通过 WebView 提供的 Web 内容进行投放的;
- Hybrid Apps,混合应用程序很受欢迎有几个原因,最大的一个是提高开发人员的生产力。如果你有一个可以在浏览器中运行的响应式 Web 应用程序,那么让相同的应用程序在各种设备上与混合应用程序一起运行是相当简单的;当你对 Web 应用进行更新时,所有使用它的设备都可以立即使用该更改,因为内容来自一个集中的服务器,而如果是纯原生应用,部署和更新时,你将不得不经历针对每个平台的构建、审核;
- 原生应用扩展,如 Microsoft Office 中类似维基百科这样的基于网络的扩展就是通过一个 WebView 实现的。
如果你对 WebView 感兴趣,可通过以下几篇文章继续了解:
Headless browser
无头浏览器是一种未配置图形用户界面 (GUI) 的 Web 浏览器,通常通过命令行或网络通信来执行。它主要由软件测试工程师使用,没有 GUI 的浏览器执行速度更快,因为它们不必绘制视觉内容。无头浏览器的最大好处之一是它们能够在没有 GUI 支持的服务器上运行。
Headless 浏览器对于测试网页特别有用,因为它们能够像浏览器一样呈现和理解超文本标记语言,包括页面布局、颜色、字体选择以及 JavaScript 和 AJAX 的执行等样式元素,这些元素在使用其他测试方法时通常是不可用的。
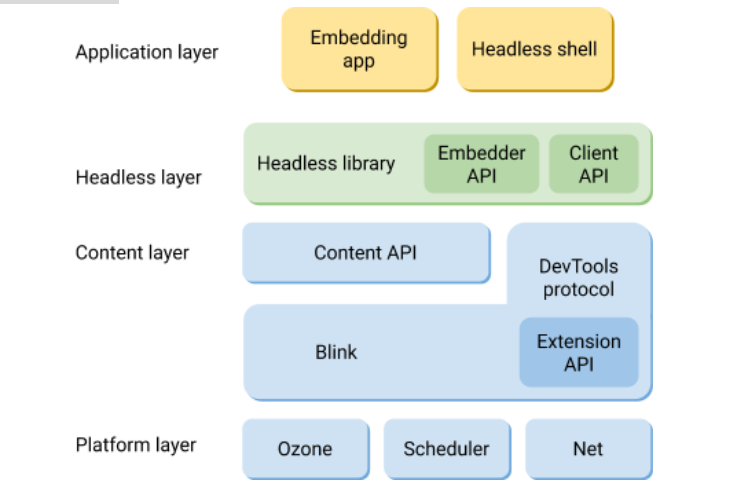
Headless 浏览器有两个主要可交付成果:
- 无头库,它允许嵌入应用程序控制浏览器并与网页交互。
- 一个无头外壳,它是一个示例应用程序,用于执行无头 API 的各种功能。
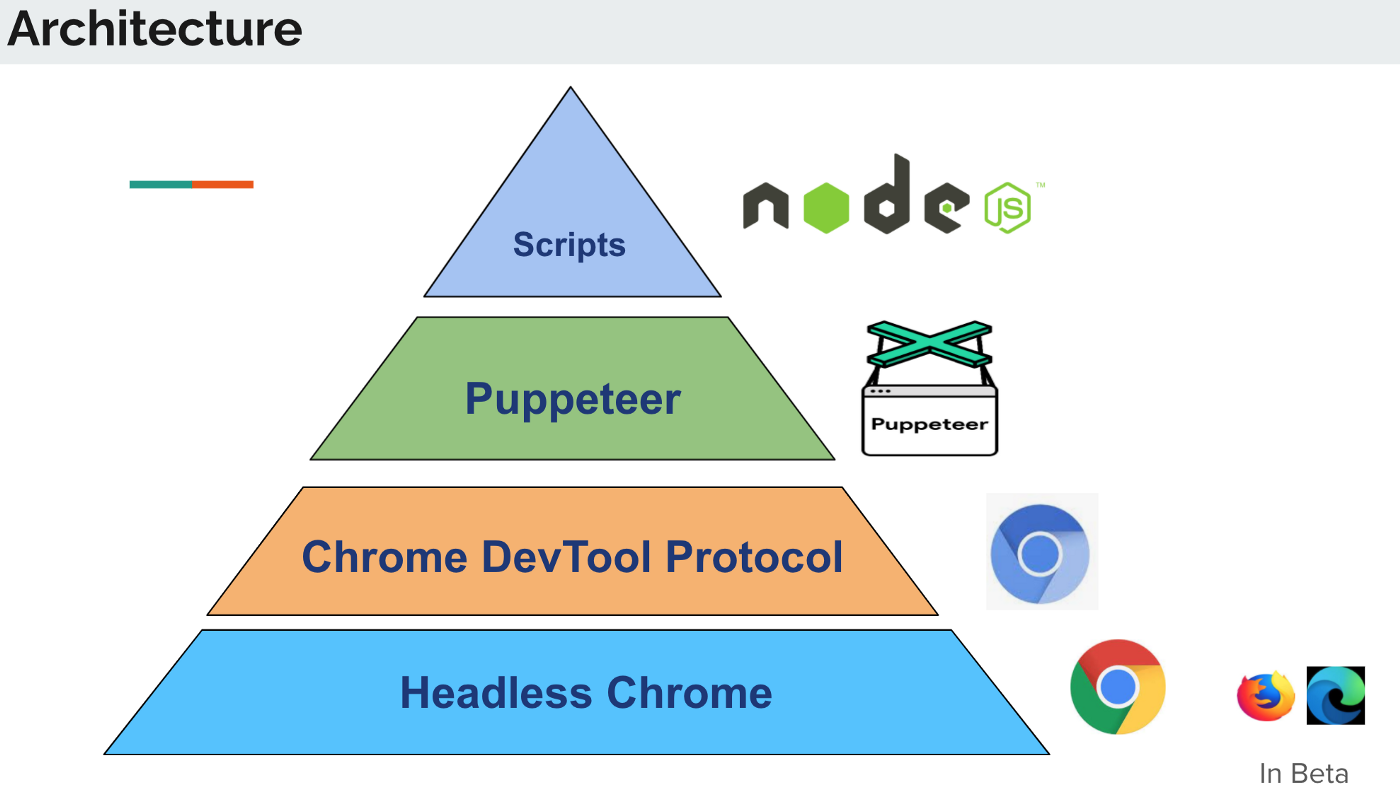
Puppeteer 是一个 Node 库,他提供了一组用来操纵 Chrome 的 API, 通俗来说就是一个 headless chrome 浏览器 (当然你也可以配置成有 UI 的,默认是没有的)。既然是浏览器,那么我们手工可以在浏览器上做的事情 Puppeteer 都能胜任, 另外,Puppeteer 翻译成中文是”木偶”意思,所以听名字就知道,操纵起来很方便,你可以很方便的操纵她去实现:
- 生成网页截图或者 PDF;
- 高级爬虫,可以爬取大量异步渲染内容的网页;
- 实现 UI 自动化测试,模拟键盘输入、表单自动提交、点击、登录网页等;
- 捕获站点的时间线,以便追踪你的网站,帮助分析网站性能问题;
- 模拟不同的设备;
- …
Puppeteer 跟 webdriver 以及 PhantomJS 最大的 的不同就是它是站在用户浏览的角度,而 webdriver 和 PhantomJS 最初设计就是用来做自动化测试的,所以它是站在机器浏览的角度来设计的,所以它们 使用的是不同的设计哲学。
Electron
Electron(原名为 Atom Shell)是 GitHub 开发的一个开源框架。它通过使用 Node.js(作为后端)和 Chromium 的渲染引擎(作为前端)完成跨平台的桌面 GUI 应用程序的开发。现已被多个开源 Web 应用程序用于前端与后端的开发,著名项目包括 GitHub 的 Atom 和微软的 Visual Studio Code。

Electron Architecture 由多个 Render Process 和一个 Main 进程组成。 Main Process 启动 Render Process,它们之间的通信是通过 IPC [Inter Process Communication],如下图所示。

我们常用的 IDE VSCode 就是基于 Electron (原来叫 Atom Shell) 进行开发的。如下图所示,(点击 VSCode 帮助【Help】 下的 切换开发人员工具即可打开以下面板)。
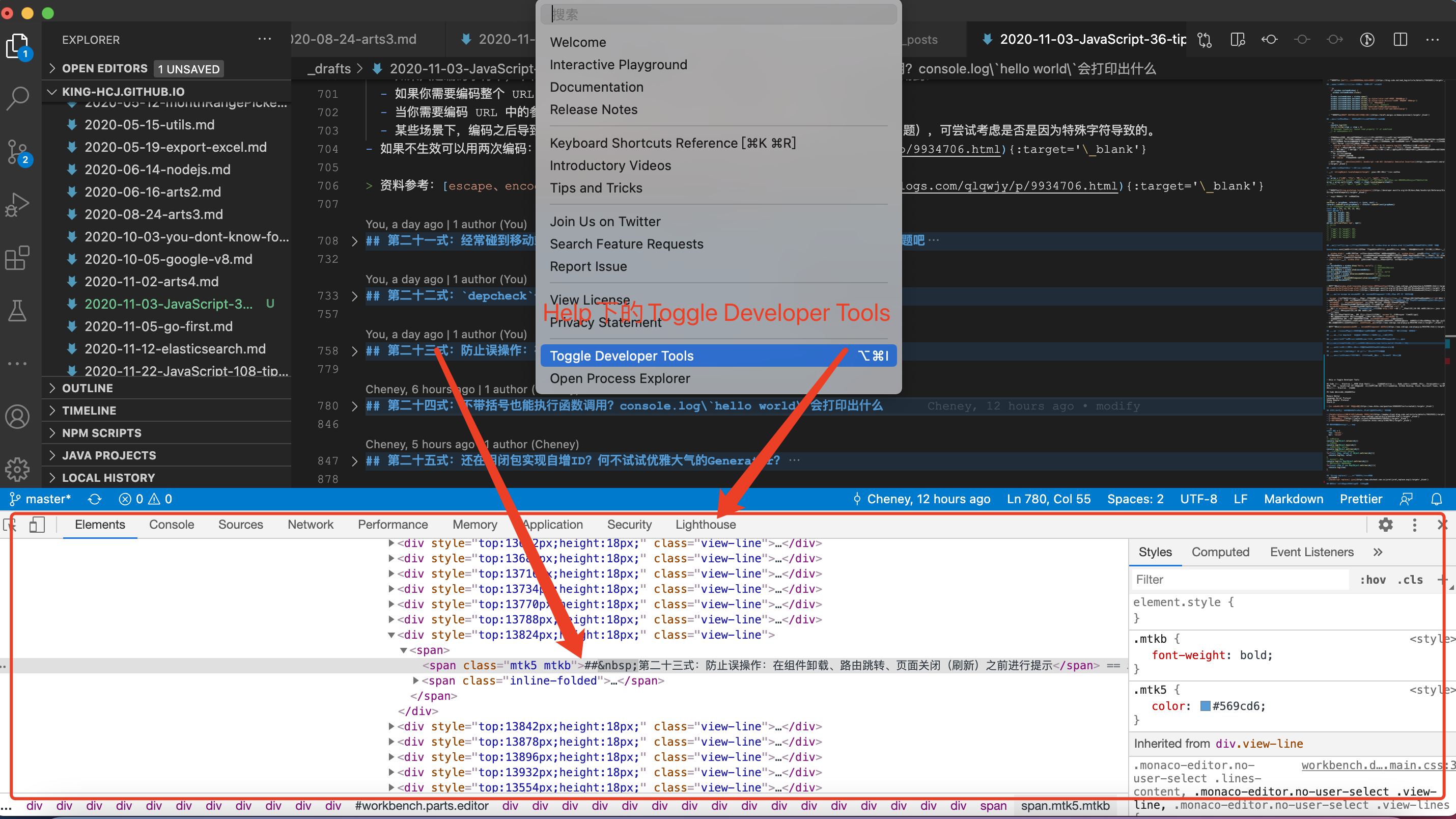
VS Code 的其他的主要组件有:
- 壳:Monaco Editor
- 内核:Language Server Protocol(一个代码编辑器)
- Debug Adapter Protocol
- Xterm.js
延伸阅读:Electron | Build cross-platform desktop apps with JavaScript, HTML, and CSS
浏览器代码兼容性测试
延伸阅读
- 浏览器简史
- Web 浏览器相关的一些概念
- 浏览器的工作原理:新式网络浏览器幕后揭秘
- 从浏览器多进程到 JS 单线程,JS 运行机制最全面的一次梳理
- 🤔 移动端 JS 引擎哪家强?美国硅谷找……
- 从 V8 角度揭秘你不知道的面试八股文
- 高性能 JavaScript 引擎 V8 - 垃圾回收
