“小马同学,背一下《陋室铭》。”“山不在高,有仙则名。水不在深,有龙则灵。斯是陋室,惟馨。”“停,怎么少了俩字?”“年轻人不讲吾德。”
系列文章发布汇总:
- 前端装逼技巧 108 式(一)—— 打工人
- 前端装逼技巧 108 式(二)—— 不讲武德
- 前端装逼技巧 108 式(三)—— 冇得感情的 API 调用工程师
- 前端装逼技巧 108 式(四)—— 一起摇摆
文章风格所限,引用资料部分,将在对应小节末尾标出。
第十九式:西施宜笑复宜颦,丑女效之徒累身 —— window.btoa、window.atob,命名这么随意的 API 可以用来干什么?
单从命名来看,完全让人摸不着头脑的两个 API,我们到底可以用他们来干些什么呢?(我甚至怀疑,如果在项目中使用这样的命名,完全可能被同事打,哈哈)
window.atob()函数用来解码一个已经被 base-64 编码过的数据。你可以使用window.btoa()方法来编码一个可能在传输过程中出现问题的数据,并且在接受数据之后,使用window.atob()方法来将数据解码。例如:你可以把 ASCII 里面数值 0 到 31 的控制字符进行编码,传输和解码。window.btoa():将 ASCII 字符串或二进制数据转换成一个 base64 编码过的字符串,该方法不能直接作用于 Unicode 字符串。- 在各浏览器中,使用
window.btoa对 Unicode 字符串进行编码都会触发一个字符越界的异常。 - 前端可以使用这两个 API 对 URL 路由参数、敏感信息等进行转码,防止明文暴露。
let encodedData = window.btoa('Hello, world'); // 编码
console.log(encodedData); // SGVsbG8sIHdvcmxk
let decodedData = window.atob(encodedData); // 解码
console.log(decodedData); // Hello, world
let encodeUTF = window.btoa(encodeURIComponent('啊'));
console.log(encodeUTF); // JUU1JTk1JThB
let decodedUTF = decodeURIComponent(atob(encodeUTF));
console.log(decodedUTF); // 啊
资料参考:window.atob()与 window.btoa()方法实现编码与解码 | WindowOrWorkerGlobalScope.atob() | WindowOrWorkerGlobalScope.btoa()
第二十式:escape、encodeURI 、 encodeURIComponent,这些编码 API 有什么区别?
escape是对字符串(string)进行编码(而另外两种是对 URL),作用是让它们在所有电脑上可读。编码之后的效果是%XX或者%uXXXX这种形式。其中 ASCII 字母、数字、@*/+,这几个字符不会被编码,其余的都会。最关键的是,当你需要对 URL 编码时,请忘记这个方法,这个方法是针对字符串使用的,不适用于 URL;encodeURI和encodeURIComponent都是编码 URL,唯一区别就是编码的字符范围;encodeURI方法不会对下列字符编码:ASCII 字母、数字、~!@#$&*()=:/,;?+';encodeURIComponent方法不会对下列字符编码:ASCII 字母、数字、~!*()';- 也就是
encodeURIComponent编码的范围更广,会将http://XXX中的//也编码,会导致 URL 不可用。(其实 java 中的URLEncoder.encode(str,char)也类似于这个方法,会导致 URL 不可用)。 - 使用场景:
- 如果只是编码字符串,不和 URL 有半毛钱关系,那么用
escape,而且这个方法一般不会用到; - 如果你需要编码整个 URL,然后需要使用这个 URL,那么用
encodeURI; - 当你需要编码 URL 中的参数的时候,那么
encodeURIComponent是最好方法; - 某些场景下,编码之后导致 URL 不可用(比如笔者曾遇到预览附件时某些附件 URL 无法打开的问题),可尝试考虑是否是因为特殊字符导致的。
- 如果只是编码字符串,不和 URL 有半毛钱关系,那么用
- 如果不生效可以用两次编码:关于两次编码的原因
第二十一式:经常碰到移动端 DNS 域名劫持问题?来一起了解下 HTTPDNS 是什么,解决了什么问题吧
对于互联网,域名是访问的第一跳,而这一跳很多时候会“失足”(尤其是移动端网络),导致访问错误内容、失败连接等,让用户在互联网上畅游的爽快瞬间消失。但凡使用域名来给用户提供服务的互联网企业,都或多或少地无法避免在有中国特色的互联网环境中遭遇到各种域名被缓存、用户跨网访问缓慢等问题。
- DNS 解析过程:
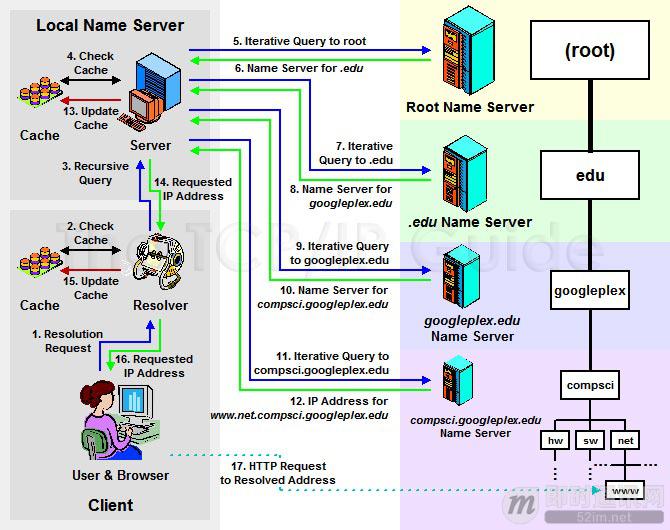
- 什么 HttpDNS:
HTTPDNS 利用 HTTP 协议与 DNS 服务器交互,代替了传统的基于 UDP 协议的 DNS 交互,绕开了运营商的 Local DNS,有效防止了域名劫持,提高域名解析效率。另外,由于 DNS 服务器端获取的是真实客户端 IP 而非 Local DNS 的 IP,能够精确定位客户端地理位置、运营商信息,从而有效改进调度精确性。
-
HttpDNS 主要解决的问题:
- Local DNS 劫持:由于 HttpDns 是通过 IP 直接请求 HTTP 获取服务器 A 记录地址,不存在向本地运营商询问 domain 解析过程,所以从根本避免了劫持问题。
- 平均访问延迟下降:由于是 IP 直接访问省掉了一次 domain 解析过程,通过智能算法排序后找到最快节点进行访问。
- 用户连接失败率下降:通过算法降低以往失败率过高的服务器排序,通过时间近期访问过的数据提高服务器排序,通过历史访问成功记录提高服务器排序。
-
HttpDNS 的原理
- 客户端直接访问 HttpDNS 接口,获取业务在域名配置管理系统上配置的访问延迟最优的 IP。(基于容灾考虑,还是保留次选使用运营商 LocalDNS 解析域名的方式);
- 客户端获取到 IP 后就直接向此 IP 发送业务协议请求。以 Http 请求为例,通过在 header 中指定 host 字段,向 HttpDNS 返回的 IP 发送标准的 Http 请求即可。
第二十二式:depcheck一下你的前端项目中是否存在未使用的依赖包
很多时候,也许我们的前端项目是基于某个已有的项目进行”复制搭建“,或者直接使用UmiJS这样的企业级 react 应用框架,又或者基于Ant Design Pro等开源项目进行删改,难免会存在未使用的依赖包,拖累项目安装速度,增大项目打包体积等,这时,我们就可以考虑使用depcheck找出那些未使用的依赖包进行移除。
npm install depcheck -g-
cd 到要检查的项目目录,运行 depcheck
D:\project>depcheck Unused devDependencies #未使用的依赖 * @antv/data-set * echarts * echarts-for-react * qs * Unused devDependencies #未使用的devDependencies * chalk * enzyme * express Missing dependencies #缺少的dependencies * immutability-helper: .\src\components\EditColums\EditColumnsTable.js * slash2: .\config\config.js
UmiJS 学习参考:UmiJS | [react]初识 Umi.JS
第二十三式:防止误操作,如何在组件卸载、路由跳转、页面关闭(刷新)之前进行提示
工作中经常会有大表单填写、提交这样的需求,如果用户写了大量内容,因为误操作,刷新或者关闭了页面,填写信息用没有做缓存,此时用户的内心应该是奔溃的。
React 组件卸载、路由跳转、页面关闭(刷新)之前进行提示(如果是 AntD Modal 弹窗里面的表单,也可视情考虑将maskClosable属性设置为 false,防止误点蒙层导致弹窗关闭):
//监听窗口事件
useEffect(() => {
const listener = (ev) => {
ev.preventDefault();
ev.returnValue = '确定离开吗?';
};
window.addEventListener('beforeunload', listener);
return () => {
// 在末尾处返回一个函数
// React 在该函数组件卸载前调用该方法(实现 componentWillUnmount)
window.removeEventListener('beforeunload', listener);
};
}, []);
第二十四式:不带括号也能执行函数调用?console.log`hello world`会打印出什么
- 直接看结果:
console.log`hello world`; // 打印出一个数组:["hello world", raw: Array(1)]
- 再看看以下代码:
const name = 'jack';
const gender = false;
// 带括号
console.log(`hey, ${name} is a ${gender ? 'girl' : 'boy'}.`); // hey, jack is a boy.
// 不带括号
console.log`hey, ${name} is a ${gender ? 'girl' : 'boy'}.`; // ["hey, ", " is a ", ".", raw: Array(3)] 'jack' 'boy'
从最后一行打印可以看出数组中的项是以’插入表达式’作为分割生成的,并且插入表答式中的内容参数,也会依次打印出来。这就是带标签的模板字符串。
- 模板字符串的语法:
// 普通
`string text` // 换行
`string text line 1
string text line 2` // 插值
`string text ${expression} string text`;
// 带标签的模板字符串
tag`string text ${expression} string text`;
- 可以做什么:
const name = 'jack';
const gender = false;
function myTagFunc(strings, name, gender) {
const sex = gender ? 'girl' : 'boy';
// return 'hello world'
return strings[0] + name + strings[1] + sex + strings[2];
}
// result 的值是myTagFunc函数的返回值
// 如果myTagFunc返回 hello world,result就是hello world
// 这样可在一定程度上避免在模板字符串内写复杂的逻辑
const result = myTagFunc`hey, ${name} is a ${gender}.`;
console.log(result); // hey, jack is a boy.
在标签函数的第一个参数中,存在一个特殊的属性 raw ,我们可以通过它来访问模板字符串的原始字符串,而不经过特殊字符的替换。
function tag(strings) {
console.log(strings.raw[0]);
}
tag`string text line 1 \n string text line 2`; // "string text line 1 \n string text line 2"
console.log`string text line 1 \n string text line 2`; // ["string text line 1 ↵ string text line 2", raw: Array(1)]
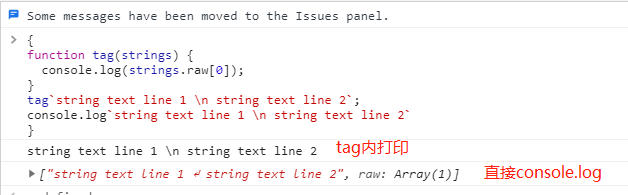
参考资料:MDN-带标签的模板字符串 | 带标签的模板字符串
第二十五式:还在用闭包实现自增 ID?何不试试优雅大气的 Generator?
- 闭包
function createIdMaker() {
let id = 1;
return function () {
return id++;
};
}
const idMaker = createIdMaker();
console.log(idMaker()); // 1
console.log(idMaker()); // 2
console.log(idMaker()); // 3
- Generator
function* createIdMaker() {
let id = 1;
while (true) yield id++;
}
const idMaker = createIdMaker();
console.log(idMaker.next().value); // 1
console.log(idMaker.next().value); // 2
console.log(idMaker.next().value); // 3
第二十六式:年轻人不讲武德,谁动了我的对象 —— 对象属性会自己偷偷排队?
程序员眼里只有女神,对象是不会有的,就算有,还能对你百依百顺不成?缺对象那就 new 一个咯,个性化定制,绝对的理想型。控制不了现实里的对象还能控制不了 new 出来的对象了?事实上,你,真的不能。
- 试想一下,下面的代码会按照什么顺序输出:
function Foo() {
this[200] = 'test-200';
this[1] = 'test-1';
this[100] = 'test-100';
this['B'] = 'bar-B';
this[50] = 'test-50';
this[9] = 'test-9';
this[8] = 'test-8';
this[3] = 'test-3';
this[5] = 'test-5';
this['D'] = 'bar-D';
this['C'] = 'bar-C';
}
var bar = new Foo();
for (key in bar) {
console.log(`index:${key} value:${bar[key]}`);
}
在 ECMAScript 规范中定义了数字属性应该按照索引值大小升序排列,字符串属性根据创建时的顺序升序排列。我们把对象中的数字属性称为排序属性,在 Chrome V8 引擎 中被称为 elements,字符串属性就被称为常规属性,在 V8 中被称为 properties。在 V8 内部,为了有效地提升存储和访问这两种属性的性能,分别使用了两个线性数据结构来分别保存排序属性和常规属性。同时 v8 将部分常规属性直接存储到对象本身,我们把这称为对象内属性 (in-object properties),不过对象内属性的数量是固定的,默认是 10 个。更多详情可参考笔者之前的一篇文章浏览器是如何工作的:Chrome V8 让你更懂 JavaScript —— 【V8 内部是如何存储对象的:快属性和慢属性】一节。
- 结果揭晓
//输出:
// index:1 value:test-1
// index:3 value:test-3
// index:5 value:test-5
// index:8 value:test-8
// index:9 value:test-9
// index:50 value:test-50
// index:100 value:test-100
// index:200 value:test-200
// index:B value:bar-B
// index:D value:bar-D
// index:C value:bar-C
第二十七式:VS Code 里竟然有谷歌开发者工具面板?它 和 Chrome 有什么关系?
如下图所示,我们经常用的开发工具 VSCode 竟与浏览器如此相像,莫非他们是失散多年的兄弟?诶,你还别说,还真有那么点意思。(点击帮助【Help】 下的 切换开发人员工具即可打开以下面板)
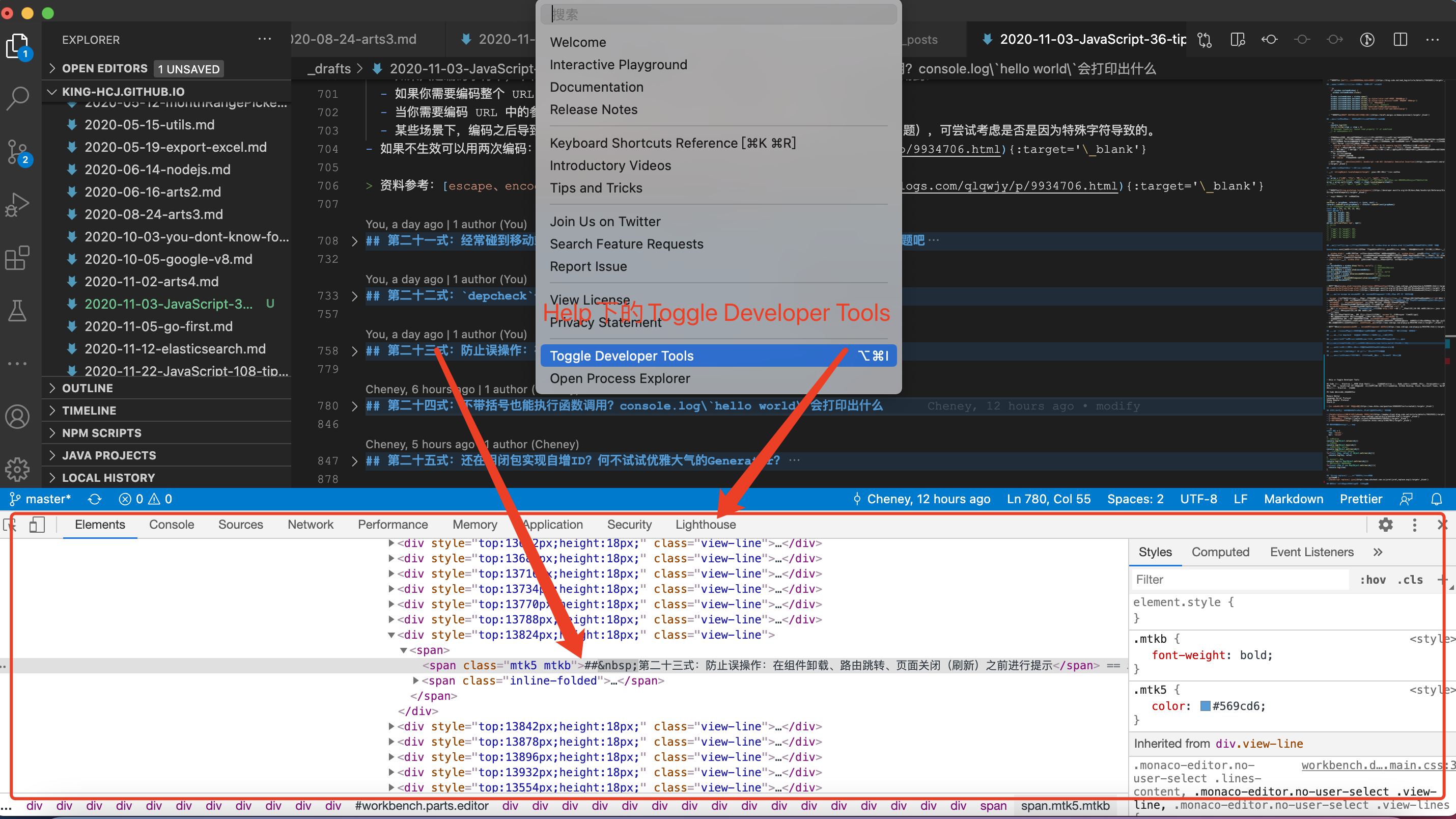
VS Code 是基于 Electron (原来叫 Atom Shell) 进行开发的。Electron 基于 Node.js(作为后端运行时)和 Chromium(作为前端渲染),使得开发者可以使用 HTML, CSS 和 JavaScript 等前端技术来开发跨平台桌面 GUI 应用程序。Atom, GitHub Desktop, Slack, Microsoft Teams, WordPress Desktop 等知名软件都是基于 Electron 开发的。Electron 比你想象的更简单,如果你可以建一个网站,你就可以建一个桌面应用程序。
VS Code 的其他的主要组件有:
- 壳:Monaco Editor
- 内核:Language Server Protocol(一个代码编辑器)
- Debug Adapter Protocol
- Xterm.js
参考资料:vs code 的界面是用的什么技术? | Electron | Electron 快速入门
第二十八式:”★★★★★☆☆☆☆☆”.slice(5 - rate, 10 - rate) —— 一个正经又有点邪气的组件封装
开始看到这行评级 rate 组件的代码,是在一篇充满邪气的文章信条|手撕吊打面试官系列面试题里,总觉得这个组件与那篇文章的文风不对应,甚至觉得这个实现还足够机智,值得借鉴,我是不是没救了,哈哈。
{
let rate = 3;
'★★★★★☆☆☆☆☆'.slice(5 - rate, 10 - rate);
}
参考资料:信条|手撕吊打面试官系列面试题
第二十九式:Uncaught TypeError: obj is not iterable,for of 遍历普通对象报错,如何快速使普通对象可被 for of 遍历?
for of可以迭代 Arrays(数组), Maps(映射), Sets(集合)、NodeList 对象、Generator 等,甚至连 Strings(字符串)都可以迭代,却不能遍历普通对象?
// 字符串
const iterable = 'ES6';
for (const value of iterable) {
console.log(value);
}
// Output:
// "E"
// "S"
// "6"
// 普通对象
const obj = {
foo: 'value1',
bar: 'value2',
};
for (const item of obj) {
console.log(item);
}
// Uncaught TypeError: obj is not iterable
我们先从对象的几个方法Object.values()、Object.keys()、Object.entries()看起吧:
const obj = {
foo: 'value1',
bar: 'value2',
};
// 打印由value组成的数组
console.log(Object.values(obj));
// 打印由key组成的数组
console.log(Object.keys(obj));
// 打印由[key, value]组成的二维数组
console.log(Object.entries(obj));
// 方法一:使用of遍历普通对象的方法
for (const [, value] of Object.entries(obj)) {
console.log(value);
}
// 普通对象转Map
console.log(new Map(Object.entries(obj)));
// 方法二:遍历普通对象生成的Map
for (const [, value] of new Map(Object.entries(obj))) {
console.log(value);
}
普通对象为何不可被for of迭代请参考下一式。
第三十式:可以遍历绝大部分数据类型的for of为什么不能遍历普通对象?
- 普通对象为何不可被
for of迭代
{
// 数组
const iterable = ['a', 'b'];
for (const value of iterable) {
console.log(value);
}
// Output:
// a
// b
}
{
// Set(集合)
const iterable = new Set([1, 2, 2, 1]);
for (const value of iterable) {
console.log(value);
}
// Output:
// 1
// 2
}
{
// Arguments Object(参数对象)
function args() {
for (const arg of arguments) {
console.log(arg);
}
}
args('a', 'b');
// Output:
// a
// b
}
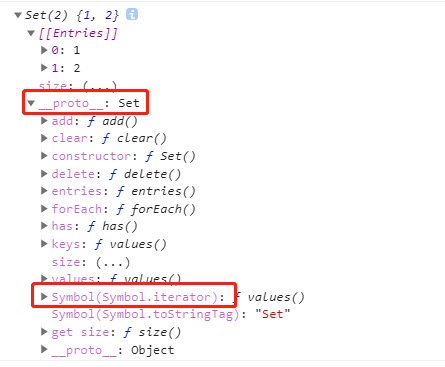
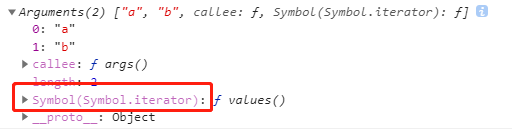

可以看到,这些可被for of迭代的对象,都实现了一个Symbol(Symbol.iterator)方法,而普通对象没有这个方法。
简单来说,for of 语句创建一个循环来迭代可迭代的对象,可迭代的对象内部实现了Symbol.iterator方法,而普通对象没有实现这一方法,所以普通对象是不可迭代的。
- 如何实现
Symbol.iterator方法,使普通对象可被for of迭代
// 普通对象
const obj = {
foo: 'value1',
bar: 'value2',
[Symbol.iterator]() {
// 不用担心[Symbol.iterator]属性会被Object.keys()获取到,
// Symbol.iterator需要通过Object.getOwnPropertySymbols(obj)获取,
// Object.getOwnPropertySymbols() 方法返回一个给定对象自身的所有 Symbol 属性的数组。
const keys = Object.keys(obj);
let index = 0;
return {
next: () => {
if (index < keys.length) {
return {
value: this[keys[index++]],
done: false,
};
} else {
return { value: undefined, done: true };
}
},
};
},
};
for (const value of obj) {
console.log(value); // value1 value2
}
参考资料:MDN:for…of | Understanding the JavaScript For…of Loop(【译文】)| Iterator 和 for…of 循环 | 迭代协议
第三十一式:position 定位只知道absolute、fixed、relative 和 static?,sticky其实可以很惊艳
- absolute:生成绝对定位的元素,相对于 static 定位以外的第一个父元素进行定位。元素的位置通过 “left”, “top”, “right” 以及 “bottom” 属性进行规定。
- fixed:生成绝对定位的元素,相对于浏览器窗口进行定位。元素的位置通过 “left”, “top”, “right” 以及 “bottom” 属性进行规定。
- relative:生成相对定位的元素,相对于其正常位置进行定位。因此,”left:20” 会向元素的 LEFT 位置添加 20 像素。
- static:默认值。没有定位,元素出现在正常的流中。
- sticky:粘性定位,该定位基于用户滚动的位置。当元素在屏幕内,它的行为就像
position:relative;, 而当页面滚动超出目标区域时,它的表现就像position:fixed;,它会固定在目标位置。
position:sticky实现的惊艳吸顶效果可点击这里。
// 用法:nav元素实现粘性定位
nav {
position: -webkit-sticky;
position: sticky;
top: 0;
}
使用position:sticky的过程中,也许会有一些坑,比如要想 sticky 生效,top 属性或则 left 属性(看滚动方向)是必须要有明确的计算值的,否则 fixed 的表现不会出现。详情可参考《CSS 世界》作者张鑫旭大佬的杀了个回马枪,还是说说 position:sticky 吧。
第三十二式:getBoundingClientRect让你找准定位不迷失自我
- 什么是
getBoundingClientRect
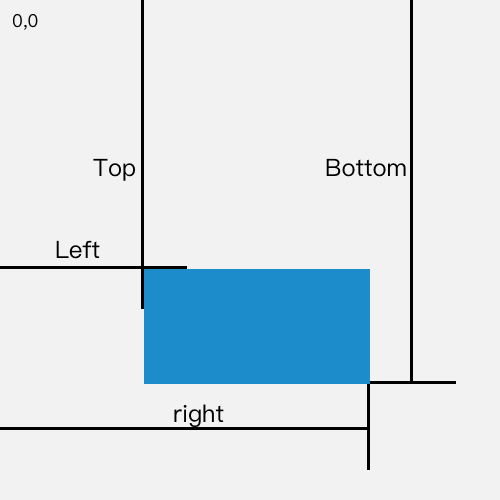
Element.getBoundingClientRect()方法,用来描述一个元素的具体位置,该位置的四个属性都是相对于视口左上角的位置而言的。对某一节点执行该方法,它的返回值是一个 DOMRect 类型的对象。这个对象表示一个矩形盒子,它含有:left、top、right 和 bottom 等只读属性,具体含义如下图所示:
-
offset 和 getBoundingClientRect() 区别
- offset 指偏移,包括这个元素在文档中占用的所有显示宽度,包括滚动条、padding、border,不包括 overflow 隐藏的部分;
- offset 的方向值需要考虑到父级,如果父级是定位元素,那么子元素的 offset 值相对于父元素;如果父元素不是定位元素,那么子元素的 offset 值相对于可视区窗口;
offsetParent:获取当前元素的定位父元素:- 如果当前元素的父元素,有 CSS 定位(position 为 absolute、relative、fixed),那么
offsetParent获取的是最近的那个父元素。 - 如果当前元素的父元素,没有 CSS 定位(position 为 absolute、relative、fixed),那么
offsetParent获取的是body。
- 如果当前元素的父元素,有 CSS 定位(position 为 absolute、relative、fixed),那么
- getBoundingClientRect() 的值只相对于可视区窗口,所以在很多场景下更容易“找准定位”。
-
能做什么:滚动吸顶效果
笔者写此节之前有做过一个表格分页器固定在浏览器底部、表头滚动吸顶的效果,主要参考了position:sticky属性和getBoundingClientRect。写此节查阅资料时有发现【前端词典】5 种滚动吸顶实现方式的比较[性能升级版] 这篇文章,对五种吸顶方式做了详尽的分析和对比,大家有兴趣可以看看。同时,《CSS 世界》作者张鑫旭大佬在杀了个回马枪,还是说说 position:sticky 吧对sticky定位也有详尽的介绍。本来还想在后续的章节谈谈吸顶,现在可能需要重新评估了,哈哈。
滚动吸顶表格示例:
【前端词典】5 种滚动吸顶实现方式的比较[性能升级版]一文中的getBoundingClientRect吸顶实现:
// html
<div class="pride_tab_fixed" ref="pride_tab_fixed">
<div class="pride_tab" :class="titleFixed == true ? 'isFixed' :''">
// some code
</div>
</div>
// vue
export default {
data(){
return{
titleFixed: false
}
},
activated(){
this.titleFixed = false;
window.addEventListener('scroll', this.handleScroll);
},
methods: {
//滚动监听,头部固定
handleScroll: function () {
let offsetTop = this.$refs.pride_tab_fixed.getBoundingClientRect().top;
this.titleFixed = offsetTop < 0;
// some code
}
}
}
参考资料:getBoundingClientRect 方法 | 杀了个回马枪,还是说说 position:sticky 吧 | 【前端词典】5 种滚动吸顶实现方式的比较[性能升级版] | JS 中的 offset、scroll、client 总结
第三十三式:Console Importer 让你的浏览器控制台成为更强大的实验场
平时开发中,我们经常会在控制台尝试一些操作,Console Importer是一个可以在 Chrome Console 面板安装(引入)loadsh、moment、jQuery、React 等资源的插件,语法也很简单,比如$i('moment')即可引入 moment 库,然后即可在控制台直接验证、使用这些库:
- 使用示例:
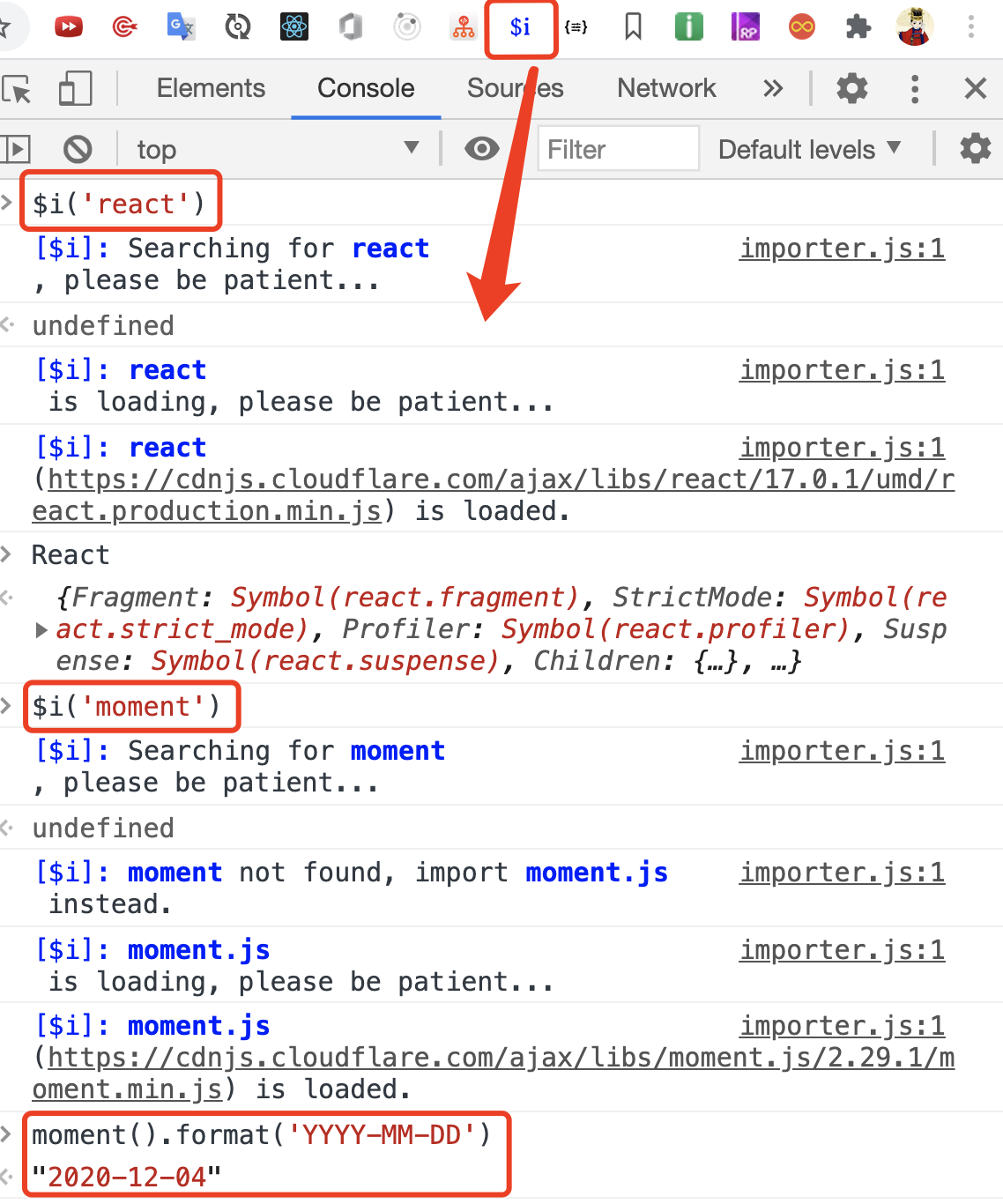
- 效果图:
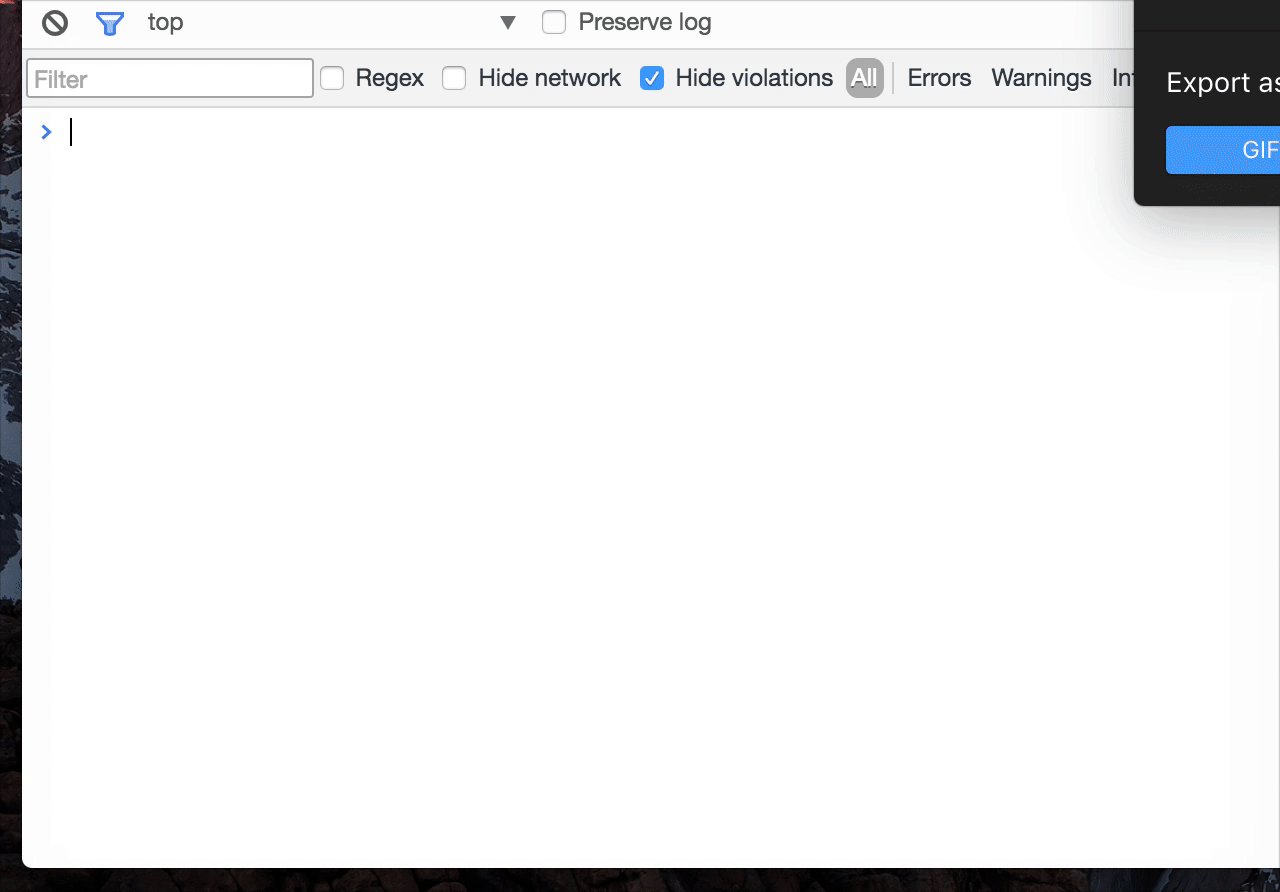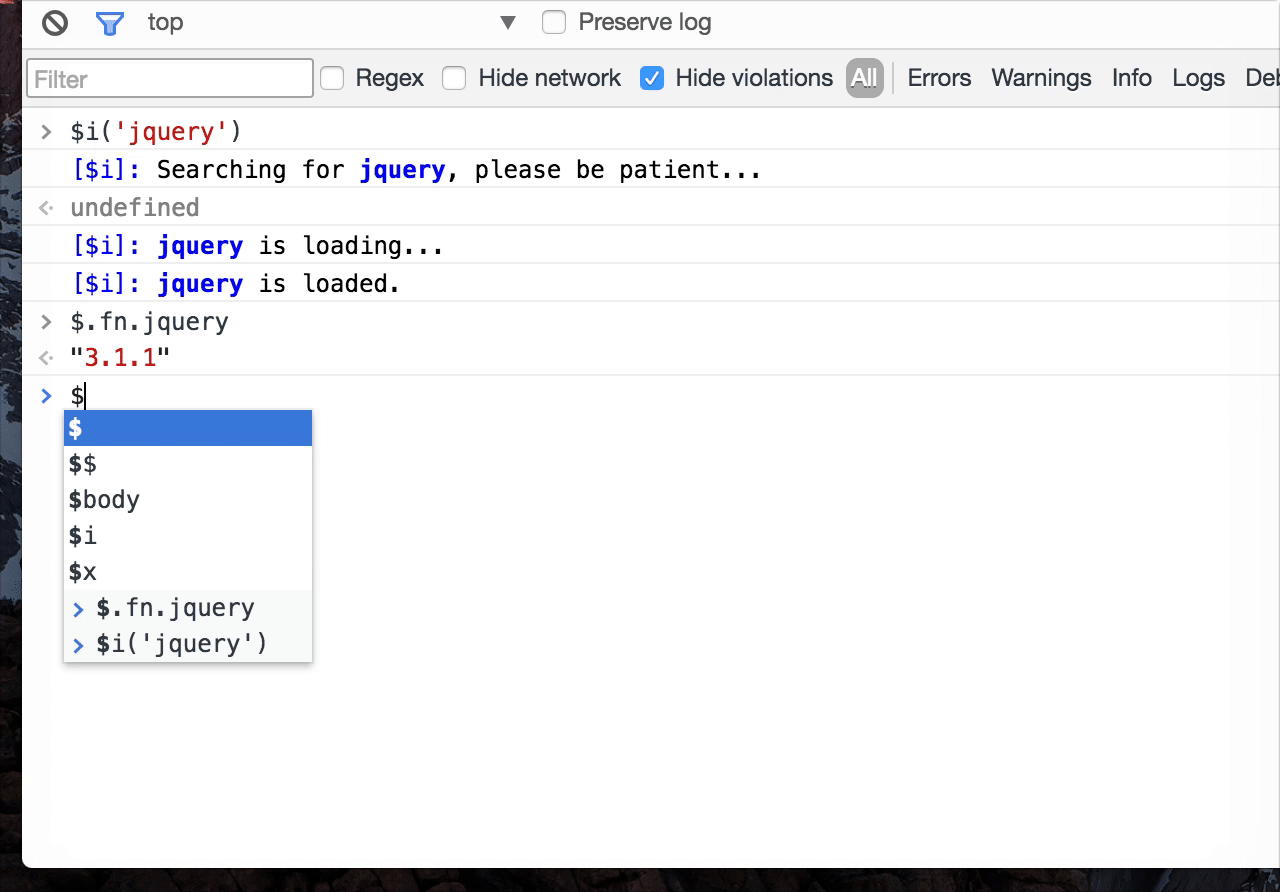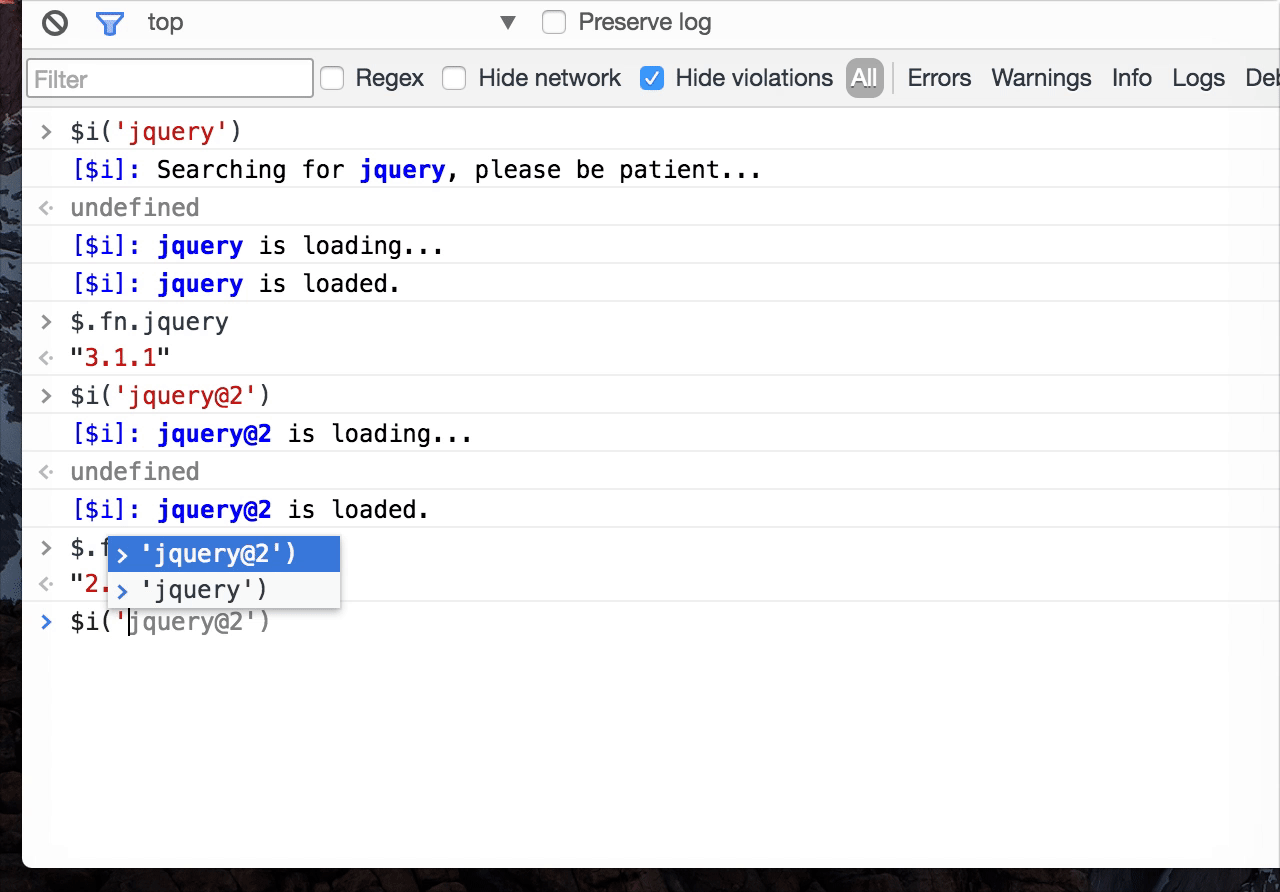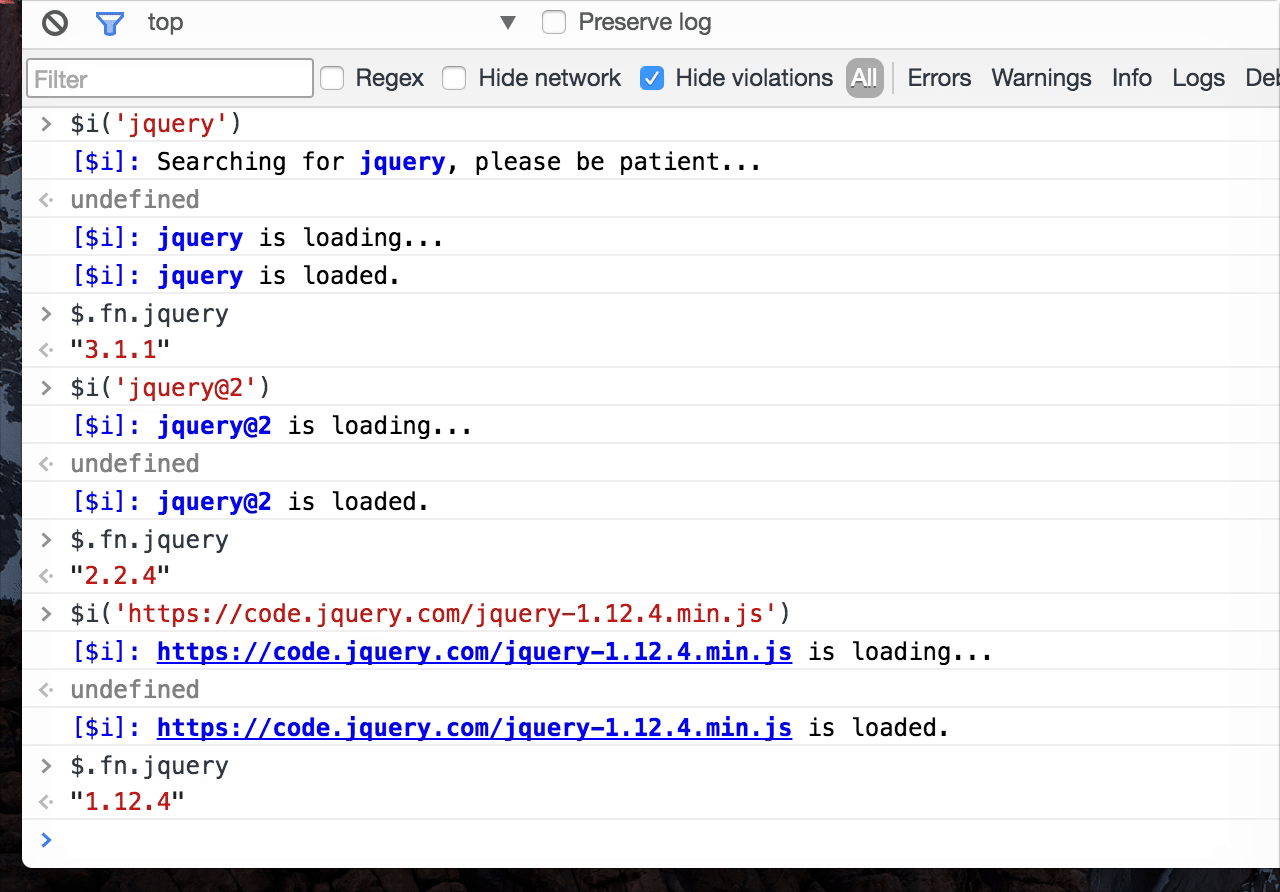
- 引入资源方法:
$i('jquery'); // 直接引入
$i('jquery@2'); // 指定版本
$i('https://cdnjs.cloudflare.com/ajax/libs/jquery/3.1.1/jquery.min.js'); // cdn地址
$i('https://maxcdn.bootstrapcdn.com/bootstrap/3.3.7/css/bootstrap.min.css'); // 引入CSS
第三十四式:误用git reset --hard,我真的没救了吗? —— 认识一下 git reflog 时光穿梭机
- 我们直奔主题,先看下面的问题:
懵懂的小白花费一周时间做了 git log 如下所示的 6 个功能,每个功能对应一个 commit 的提交,分别是 feature-1 到 feature-6”:
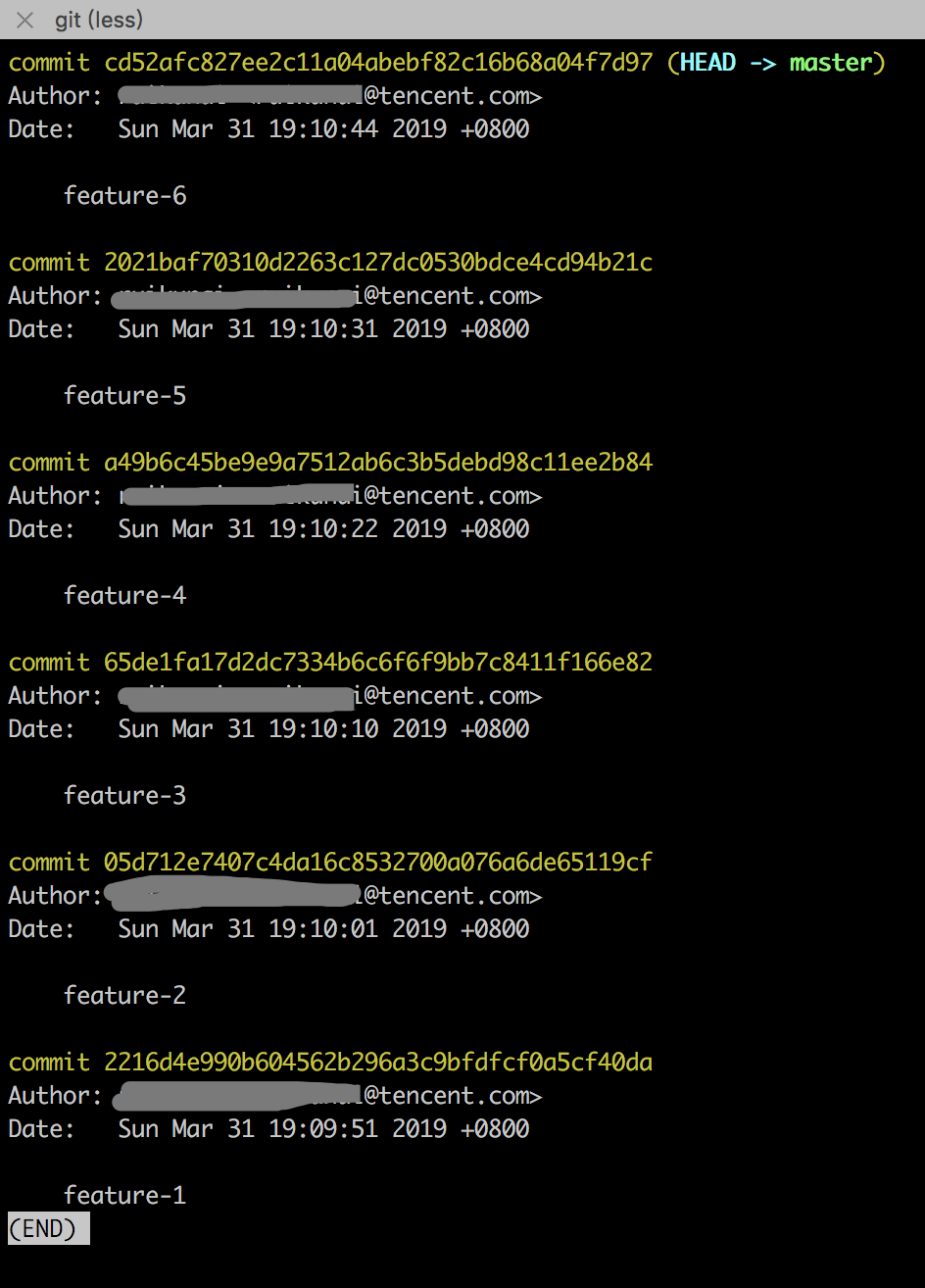
然后错误的执行了强制回滚,git reset --hard 2216d4e,回滚到了 feature-1 上,并且回滚的时候加了–hard,导致之前 feature-2 到 feature-6 的所有代码全部弄丢了,现在 git log 上显示如下:
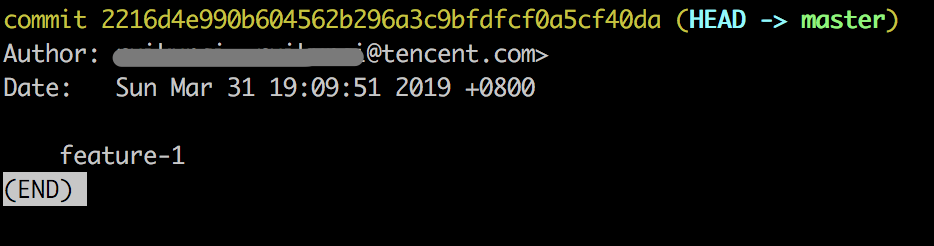
然后,又在此基础上新添加了一个 commit 提交,信息叫 feature-7:
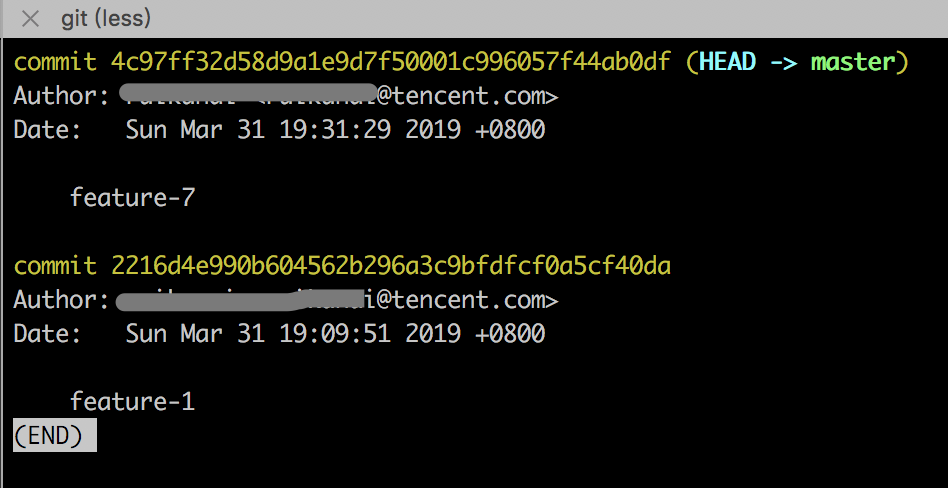
请问:如何把丢失的代码 feature-2 到 feature-6 全部恢复回来,并且 feature-7 的代码也要保留
-
接下来,我们回忆几个 git 命令:
git reset --hard撤销工作区中所有未提交的修改内容,将暂存区与工作区都回到上一次版本,并删除之前的所有信息提交,谨慎使用 –hard 参数,它会删除回退点之前的所有信息;git log命令可以显示所有提交过的版本信息;git reflog可以查看所有分支的所有操作记录(包括已经被删除的 commit 记录和 reset 的操作);git cherry-pick命令的作用,就是将指定的提交(commit)应用于其他分支。
-
最后,给出解答:
git reflog和git cherry-pick- 首先,使用
git reflog查看所以 git 操作记录,记下 feature-7 和 feature-6 的 hash 码。
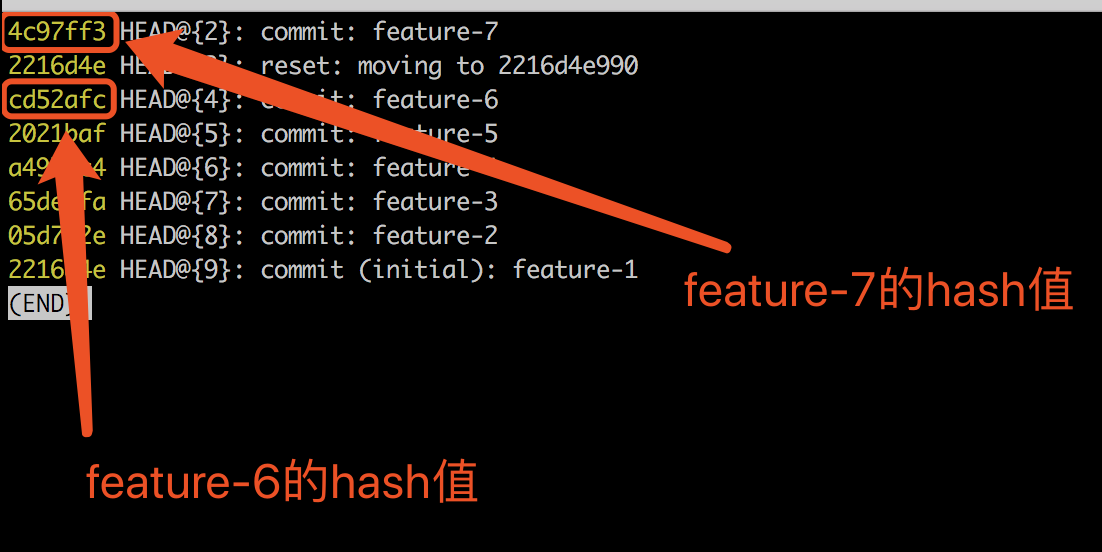
- 其次,
git reset --hard cd52afc回滚到 feature-6。此时我们已经完成了要求的一半:成功回到了 feature-6 上,但是 feature-7 没了。 - 最后,
git cherry-pick 4c97ff3,执行完成之后,feature-7 的代码就回来了,大功告成。
- 首先,使用
更多 git 知识点推荐阅读 GitHub 联合创始人 Scott Chacon 和 Ben Straub 的开源巨作《Pro Git》
第三十五式:文件上传只会使用 form 和 Ant Design Upload 组件?
最近有做一个由其他部门提供接口的需求,上传文件的接口文档如下图所示,文件内容是 base64 格式,且要和其他参数一起传递。笔者以前做的需求,上传文件一般是通过 form、Ant Design Upload 组件、FormData 等方式,上传成功得到一个 URL,表单提交时将得到的 URL 传给后端;下载通过 Blob、后端返回 URL、发送邮件、或者前端生成 Excel等方式。这次的上传使用了 FileReader,简单记录相关实现。关于大文件的上传和下载,之后的章节会进行探讨。
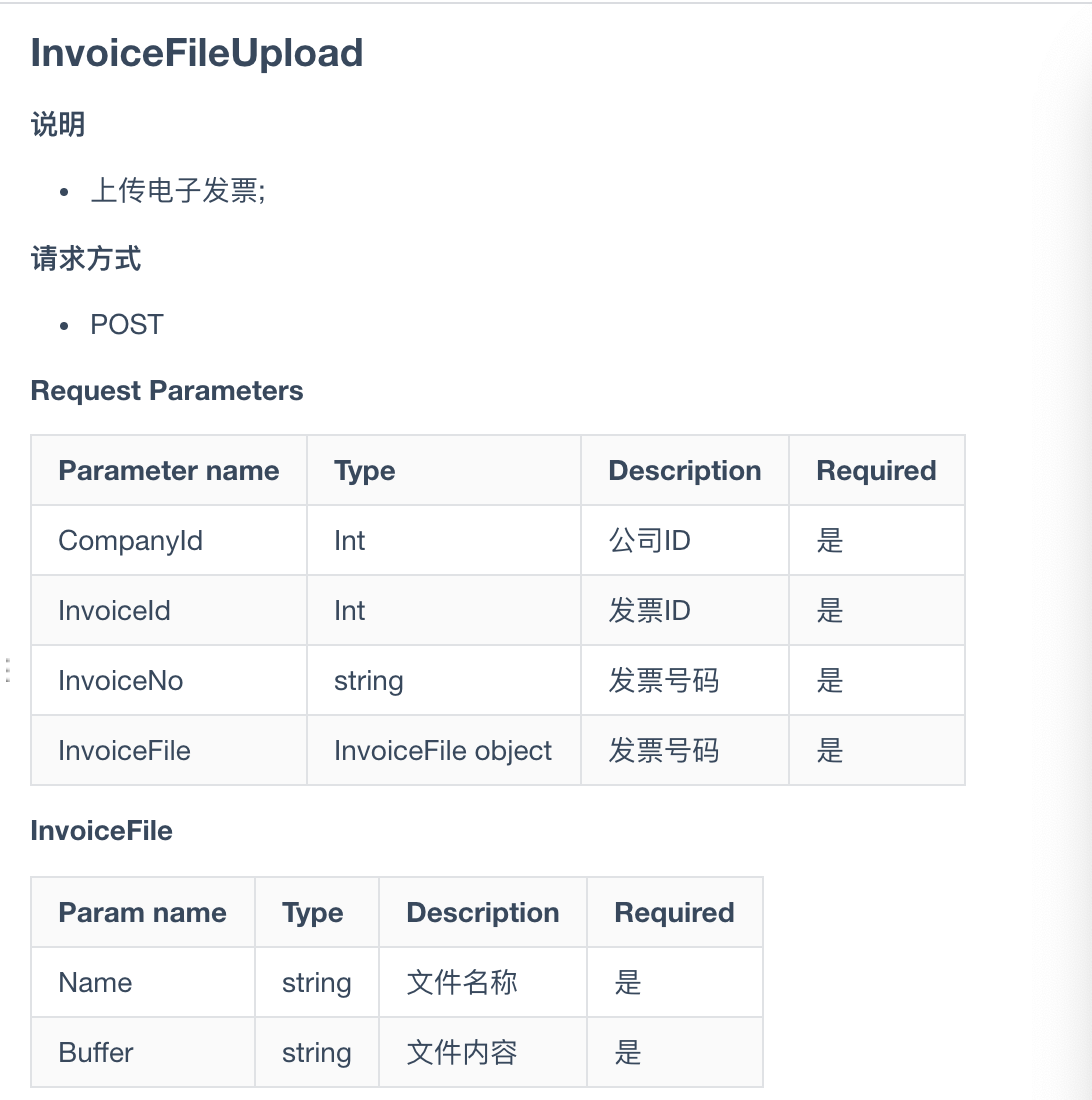
- 代码实现
// DOM
<input type='file' id='file' onChange={(e) => this.uploadFile(e)} />
// js
uploadFile(e) {
const file = e.target.files[0];
const reader = new FileReader();
// 处理loadend事件。该事件在读取操作结束时(要么成功,要么失败)触发。
reader.onloadend = () => {
this.setState({
// 存储
XXXFile: {
// 除了name外,file中可被读取的属性还包括size、type、lastModifiedDate
Name: file.name,
// base64格式文件数据
// 一次性发送大量的base64数据会导致浏览器卡顿,服务器端接收这样的数据可能也会出现问题。
Buffer: reader.result.replace(/data.*base64[,]/, '')
}
})
}
reader.readAsDataURL(file);
}
-
FileReader 方法拓展:
FileReader.abort():中止读取操作。在返回时,readyState 属性为 DONE。FileReader.readAsArrayBuffer():开始读取指定的 Blob 中的内容, 一旦完成, result 属性中保存的将是被读取文件的 ArrayBuffer 数据对象.FileReader.readAsBinaryString():开始读取指定的 Blob 中的内容。一旦完成,result 属性中将包含所读取文件的原始二进制数据。FileReader.readAsDataURL():开始读取指定的 Blob 中的内容。一旦完成,result 属性中将包含一个data: URL格式的 Base64 字符串以表示所读取文件的内容。FileReader.readAsText():开始读取指定的 Blob 中的内容。一旦完成,result 属性中将包含一个字符串以表示所读取的文件内容。
-
其他文件上传参考资料:
第三十六式:2**53 === 2 ** 53 + 1?如果没有 BigInt,该如何进行大数求和?
Number.MAX_SAFE_INTEGER:值为9007199254740991,即2 ** 53 - 1,小于该值能精确表示。然后我们会发现2**53 === 2 ** 53 + 1为true。Number.MAX_VALUE::值为1.7976931348623157e+308,大于该值得到的是Infinity,介于Infinity和安全值之间的无法精确表示。
既然我们不能实现直接相加,我们可以利用字符串分割成字符串数组的方式来对每一位进行相加。
- 大数相加实现
function add(str1, str2) {
// 转为数组
str1 = (str1 + '').split('');
str2 = (str2 + '').split('');
let result = ''; //存储结果
let flag = 0; // 存储进位
while (str1.length || str2.length || flag) {
// 是否还有没有相加的位或者大于0的进位
// ~~str1.pop()得到最右边一位,并转成数字(~为按位取反运算符,详见第十四式)
// 对应位数字相加,再加上进位
flag += ~~str1.pop() + ~~str2.pop();
// 去除进位,然后进行字符串拼接
result = (flag % 10) + result;
// 进位,0或1
flag = +(flag > 9);
}
// 去除开头(高位)的0
return result.replace(/^0+/, '');
}
// 2 ** 53:9007199254740992
// add(2**53, 1): "9007199254740993"
// 2**53+1: 9007199254740992
// BigInt结果
// 2n**53n+1n:9007199254740993n
- 加减乘除:
关于加减乘除的实现可参考大数运算 js 实现,基本思路:
- 大数加法和减法是一个道理,既然我们不能实现直接相加减,我们可以利用字符串分割成字符串数组的方式。
- 乘法:每个位数两两相乘,最后错位相加。
