敲一夜代码,流两行老泪;用三种语言,唯四肢受罪 ; 待五更鸡鸣,遇骤雨初歇;遂登门而去,伫十里长亭;欲望穿泪眼,无如意郎君;借微薄助力,愿寻得佳偶;成比翼双鸟,乃畅想云端;卷情网之内,做爬虫抓取;为连理桂枝,容数据分析;思千里子规,助框广天地; 念茫茫人海,该如何寻觅?
系列文章发布汇总:
- 前端装逼技巧 108 式(一)—— 打工人
- 前端装逼技巧 108 式(二)—— 不讲武德
- 前端装逼技巧 108 式(三)—— 冇得感情的 API 调用工程师
- 前端装逼技巧 108 式(四)—— 一起摇摆
文章风格所限,引用资料部分,将在对应小节末尾标出。
第三十七式:茫然一顾眼前亮,懵懂宛如在梦中 —— "1234".length === 5 ?这一刻,我感受到了眼睛的背叛和侮辱
- 复制以下代码到浏览器控制台:
console.log('1234'.length === 5); // true
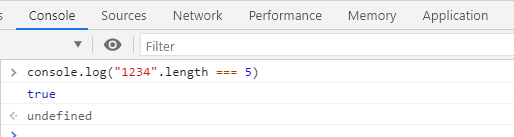
哈哈,是不是有种被眼睛背叛的感觉?其实这就是所谓的零宽空格(Zero Width Space,简称“ZWSP”),零宽度字符是不可见的非打印字符,它用于打断长英文单词或长阿拉伯数字,以便于换行显示,否则长英文单词和长阿拉伯数字会越过盒模型的边界,常见于富文本编辑器,用于格式隔断。
- 探究以下上面代码的玄机:
const common = '1234';
const special = '1234';
console.log(common.length); // 4
console.log(special.length); // 5
console.log(encodeURIComponent(common)); // 1234
console.log(encodeURIComponent(special)); // 123%E2%80%8B4
// 把上面中间特殊字符部分进行解码
console.log(decodeURIComponent('%E2%80%8B')); // (空)
const otherSpecial = '123\u200b4'; // 或者"123\u{200b}4"
console.log(otherSpecial); // 1234
console.log(otherSpecial.length, common === special, special === otherSpecial); // 5 false true
- 在 HTML 中使用零宽度空格(在 HTML 中,零宽度空格与
<wbr>等效):
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<meta http-equiv="X-UA-Compatible" content="ie=edge" />
<title>Document</title>
</head>
<body>
<!-- ​ 和 <wbr /> 是零宽空格在html中的两种表示 -->
<div>abc​def</div>
<div>abc<wbr />def</div>
</body>
</html>
ESLint 有一条禁止不规则的空白 (no-irregular-whitespace)的规则,防止代码里面误拷贝了一些诸如零宽空格类的空格,以免造成一些误导。
拓展:我们经常在 html 中使用的
全称是No-Break SPace,即不间断空格,当 HTML 有多个连续的普通空格时,浏览器在渲染时只会渲染一个空格,而使用这个不间断空格,可以禁止浏览器合并空格。常用于富文本编辑器之中,当我们在富文本编辑器连续敲下多个空格时,最后输出的内容便会带有很多不间断空格。
参考资料:常见空格一览 - 李银城 | 什么是零宽度空格 | 维基百科-空格
第三十八式:如何禁止网页复制粘贴
对于禁止网页复制粘贴,也许你并不陌生。一些网页是直接禁止复制粘贴;一些网页,则是要求登陆后才可复制粘贴;还有一些网站,复制粘贴时会带上网站的相关来源标识信息。
- 如何禁止网页复制粘贴
const html = document.querySelector('html');
html.oncopy = () => {
alert('牛逼你复制我呀');
return false;
};
html.onpaste = () => false;
- 在复制时做些别的操作,比如跳转登陆页面
const html = document.querySelector('html');
html.oncopy = (e) => {
console.log(e);
// 比如指向百度或者登陆页
// window.location.href='http://www.baidu.com';
};
html.onpaste = (e) => {
console.log(e);
};
- 如何使用 js 设置/获取剪贴板内容
//设置剪切板内容
document.addEventListener('copy', () => {
const clipboardData =
event.clipboardData || event.originalEvent?.clipboardData;
clipboardData?.setData('text/plain', '不管复制什么,都是我!');
event.preventDefault();
});
//获取剪切板的内容
document.addEventListener('paste', () => {
const clipboardData =
event.clipboardData || event.originalEvent?.clipboardData;
const text = clipboardData?.getData('text');
console.log(text);
event.preventDefault();
});
-
有什么用
- 对于注册输入密码等需要输入两次相同内容的场景,应该是需要禁止粘贴的,这时候就可以禁止对应输入框的复制粘贴动作。
- 登陆才能复制。很多网站上的页面内容是不允许复制的,这样可以防止用户或者程序恶意的去抓取页面数据。
第三十九式:function.length指代什么? —— 柯里化,JS 函数重载
在函数式编程里,有几个比较重要的概念:函数的合成、柯里化和函子。其中柯里化(Currying),是指把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数而且返回结果的新函数的技术。这个技术由 Christopher Strachey 以逻辑学家 Haskell Curry 命名的,但是它是 Moses Schnfinkel 和 Gottlob Frege 发明的。
lodash 实现了_.curry函数,_.curry函数接收一个函数作为参数,返回新的柯里化(curry)函数。调用新的柯里化函数时,当传递的参数个数小于柯里化函数要求的参数时,返回一个接收剩余参数的函数,当传递的参数达到柯里化函数要求时,返回结果。那么,\_.curry函数是如何判断传递的参数是否到达要求的呢?我们不妨先看看下面的例子:
function func(a, b, c) {
console.log(func.length, arguments.length);
}
func(1); // 3 1
-
看看 MDN 的解释:
length是函数对象的一个属性值,指该函数有多少个必须要传入的参数,那些已定义了默认值的参数不算在内,比如 function(x = 0)的 length 是 0。即形参的数量仅包括第一个具有默认值之前的参数个数。- 与之对比的是,
arguments.length是函数被调用时实际传参的个数。
-
实现 lodash curry 化函数
// 模拟实现 lodash 中的 curry 方法
function curry(func) {
return function curriedFn(...args) {
// 判断实参和形参的个数
if (args.length < func.length) {
return function () {
return curriedFn(...args.concat(Array.from(arguments)));
};
}
return func(...args);
};
}
function getSum(a, b, c) {
return a + b + c;
}
const curried = curry(getSum);
console.log(curried(1, 2, 3));
console.log(curried(1)(2, 3));
console.log(curried(1, 2)(3));
- JS 函数重载
函数重载,就是函数名称一样,但是允许有不同输入,根据输入的不同,调用不同的函数,返回不同的结果。JS 里默认是没有函数重载的,但是有了Function.length属性和arguments.length,我们便可简单的通过if…else或者switch来完成 JS 函数重载了。
function overLoading() {
// 根据arguments.length,对不同的值进行不同的操作
switch (arguments.length) {
case 0 /*操作1的代码写在这里*/:
break;
case 1 /*操作2的代码写在这里*/:
break;
case 2: /*操作3的代码写在这里*/
}
}
更高级的函数重载,请参考 jQuery 之父 John Resig 的JavaScript Method Overloading, 这篇文章里,作者巧妙地利用闭包,实现了 JS 函数的重载。
参考资料:浅谈 JavaScript 函数重载 | JavaScript Method Overloading | 【译】JavaScript 函数重载 - Fundebug | Function.length | 函数式编程入门教程 - 阮一峰
第四十式:["1","7","11"].map(parseInt)为什么会返回[1,NaN,3]?
- map 返回 3 个参数,item,index,Array,所以
[1,7,11].map(console.log)打印:
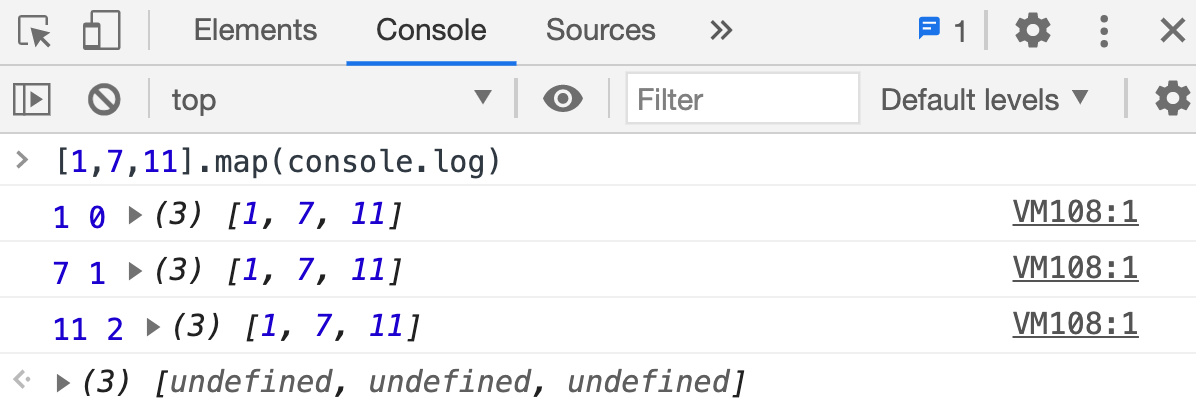
- parseInt 接受两个参数:string,radix,其中 radix 默认为 10;
- 那么,每次调用 parseInt,相当于:
parseInt(item,index,Array),map 传递的第三个参数 Array 会被忽略。index 为 0 时,parseInt(1,0),radix 取默认值 10;parseInt(7,1)中,7 在 1 进制中不存在,所以返回”NaN“;parseInt(11,2),2 进制中 11 刚好是十进制中的 3。
第四十一式:iframe 间数据传递,postMessage 可以是你的选择
平时开发中,也许我们会遇到需要在非同源站点、iframe 间传递数据的情况,这个时候,我们可以使用 postMessage 完成数据的传递。 window.postMessage() 方法可以安全地实现跨源通信。通常,对于两个不同页面的脚本,只有当执行它们的页面位于具有相同的协议(通常为 https),端口号(443 为 https 的默认值),以及主机 (两个页面的模数 Document.domain 设置为相同的值) 时,这两个脚本才能相互通信(即同源)。window.postMessage() 方法提供了一种受控机制来规避此限制,只要正确的使用,这种方法就很安全。
// 页面1 触发事件,发送数据
top.postMessage(data, '*');
// window 当前所在iframe
// parent 上一层iframe
// top 最外层iframe
//页面2 监听message事件
useEffect(() => {
const listener = (ev) => {
console.log(ev, ev.data);
};
window.addEventListener('message', listener);
return () => {
window.removeEventListener('message', listener);
};
}, []);
注意:
postMessage第二个参数 targetOrigin 用来指定哪些窗口能接收到消息事件,其值可以是字符串”*“(表示无限制)或者一个 URI。- 如果你明确的知道消息应该发送到哪个窗口,那么请始终提供一个有确切值的 targetOrigin,而不是*。
-
不提供确切的目标将导致数据泄露到任何对数据感兴趣的恶意站点。
- 参考资料:window.postMessage
第四十二式:薛定谔的 X —— 有趣的let x = x
薛定谔的猫(英文名称:Erwin Schrödinger’s Cat)是奥地利著名物理学家薛定谔提出的一个思想实验,是指将一只猫关在装有少量镭和氰化物的密闭容器里。镭的衰变存在几率,如果镭发生衰变,会触发机关打碎装有氰化物的瓶子,猫就会死;如果镭不发生衰变,猫就存活。根据量子力学理论,由于放射性的镭处于衰变和没有衰变两种状态的叠加,猫就理应处于死猫和活猫的叠加状态。这只既死又活的猫就是所谓的“薛定谔猫”。
JS 引入 let 和 const 之后,也出现了一种有趣的现象:
<!-- 可以拷贝下面的代码,放的一个html文件中,然后使用浏览器打开,查看控制台 -->
<!-- index.html -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
</head>
<body>
<script>
let x = x;
</script>
<script>
x = 2;
console.log(x);
</script>
</body>
</html>
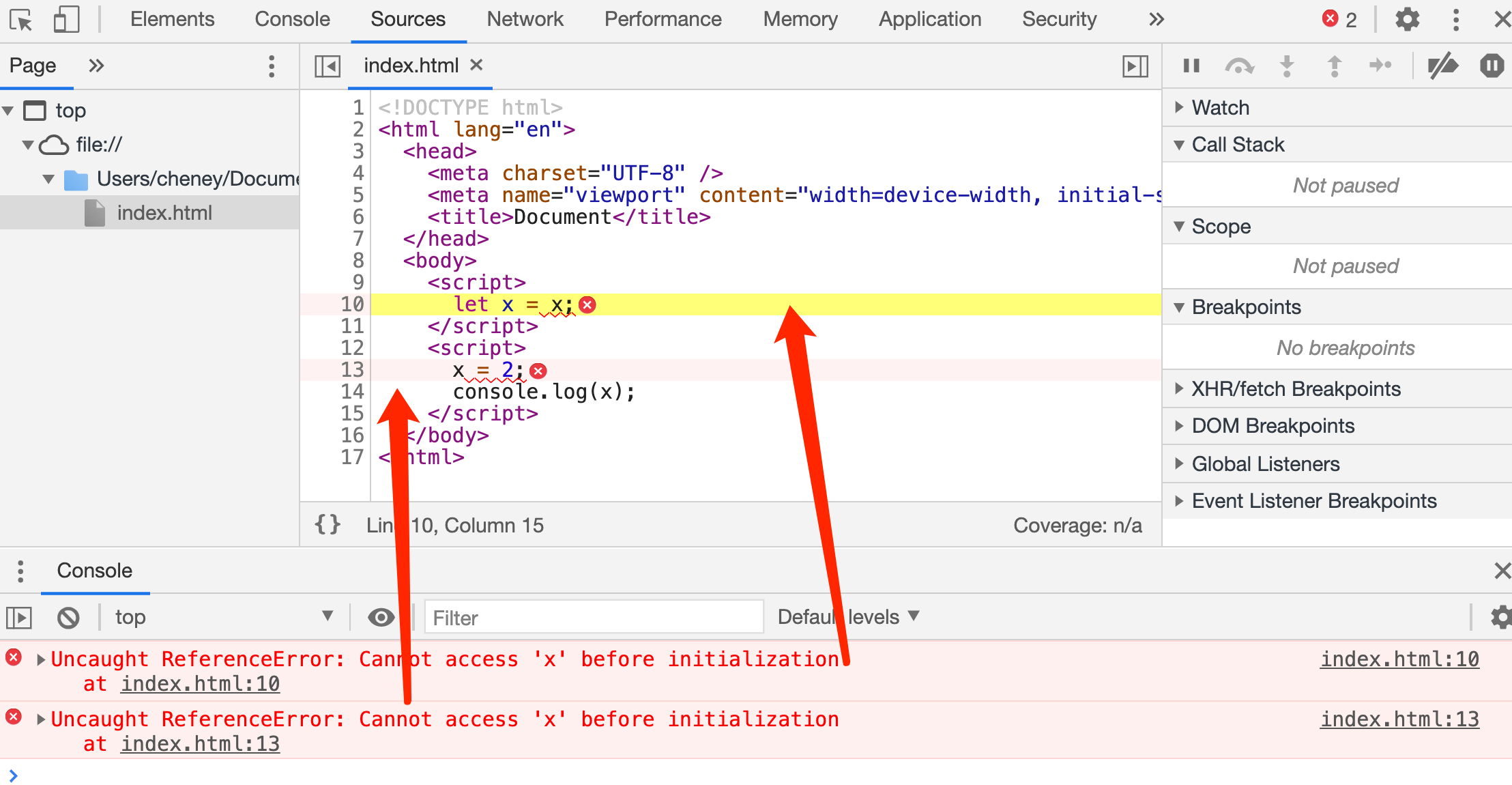
上面的代码里,我们在第一个 script 里引入写了let x = x;,就导致在其他 script 下都无法在全局作用域下使用 x 变量了(无论是对 x 进行赋值、取值,还是声明,都不行)。也就是说现在 x 处于一种“既被定义了,又没被定义”的中间状态。
这个问题说明:如果 let x 的初始化过程失败了,那么:
- x 变量就将永远处于 created 状态。
- 你无法再次对 x 进行初始化(初始化只有一次机会,而那次机会你失败了)。
- 由于 x 无法被初始化,所以 x 永远处在暂时死区(也就是盗梦空间里的 limbo)!
- 有人会觉得 JS 坑,怎么能出现这种情况;其实问题不大,因为此时代码已经报错了,后面的代码想执行也没机会。
参考资料:JS 变量封禁大法:薛定谔的 X
第四十三式:聊聊前端错误处理
一个 React-dnd 引出的前端错误处理
年初的时候,笔者曾做过一个前端错误处理的笔记,事情是这样的:
项目中某菜单定义的页面因有拖拽的需求,就引入了React DnD来完成这一工作;随着业务的更新迭代,部分列表页面又引入了自定义列的功能,可以通过拖动来对列进行排序,后面就发现在某些页面上,试图打开自定义列的弹窗时,页面就崩溃白屏了,控制台会透出错误:'Cannot have two HTML5 backends at the same time.'。在排查问题的时候,查看源码发现:
// ...
value: function setup() {
if (this.window === undefined) {
return;
}
if (this.window.__isReactDndBackendSetUp) {
throw new Error('Cannot have two HTML5 backends at the same time.');
}
this.window.__isReactDndBackendSetUp = true;
this.addEventListeners(this.window);
}
// ...
也就是说,react-dnd-html5-backend在创建新的实例前会通过window.__isReactDndBackendSetUp的全局变量来判断是否已经存在一个可拖拽组件,如果有的话,就直接报错,而由于项目里对应组件没有相应的错误处理逻辑,抛出的 Error 异常层层上传到 root,一直没有被捕获和处理,最终导致页面崩溃。其实在当是的业务场景下,这个问题比较好解决,因为菜单定义页面没有自定义列的需求,而其他页面自定义列又是通过弹窗展示的,所以不要忘了给自定义列弹窗设置 destroyOnClose 属性(关闭销毁)即可。为了避免项目中因为一些错误导致系统白屏,在项目中,我们应该合理使用错误处理。
前端错误处理的方法
Error Boundaries
如何使一个 React 组件变成一个“Error Boundaries”呢?只需要在组件中定义个新的生命周期函数——componentDidCatch(error, info):
error: 这是一个已经被抛出的错误;info:这是一个 componentStack key。这个属性有关于抛出错误的组件堆栈信息。
// ErrorBoundary实现
class ErrorBoundary extends React.Component {
state = { hasError: false };
componentDidCatch(error, info) {
// Display fallback UI
this.setState({ hasError: true });
// You can also log the error to an error reporting service
logErrorToMyService(error, info);
}
render() {
if (this.state.hasError) {
// You can render any custom fallback UI
return <h1>Something went wrong.</h1>;
}
return this.props.children;
}
}
ErrorBoundary 使用:
// ErrorBoundary使用
<ErrorBoundary>
<MyWidget />
</ErrorBoundary>
Erro Boundaries 本质上也是一个组件,通过增加了新的生命周期函数 componentDidCatch 使其变成了一个新的组件,这个特殊组件可以捕获其子组件树中的 js 错误信息,输出错误信息或者在报错条件下,显示默认错误页。注意一个 Error Boundaries 只能捕获其子组件中的 js 错误,而不能捕获其组件本身的错误和非子组件中的 js 错误。
但是 Error Boundaries 也不是万能的,下面我们来看哪些情况下不能通过 Error Boundaries 来 catch{}错误:
- 组件的内部的事件处理函数,因为 Error Boundaries 处理的仅仅是 Render 中的错误,而 Hander Event 并不发生在 Render 过程中。
- 异步函数中的异常 Error Boundaries 不能 catch,比如 setTimeout 或者 setInterval ,requestAnimationFrame 等函数中的异常。
- 服务器端的 rendering
- 发生在 Error Boundaries 组件本身的错误
componentDidCatch()生命周期函数:
componentDidCatch 是一个新的生命周期函数,当组件有了这个生命周期函数,就成为了一个 Error Boundaries。
try/catch 模块
Error Boundaries 仅仅抛出了子组件的错误信息,并且不能抛出组件中的事件处理函数中的异常。(因为 Error Boundaries 仅仅能保证正确的 render,而事件处理函数并不会发生在 render 过程中),我们需要用 try/catch 来处理事件处理函数中的异常。
try/catch 只能捕获到同步的运行时错误,对语法和异步错误却无能为力,捕获不到。
window.onerror
当 JS 运行时错误发生时,window 会触发一个 ErrorEvent 接口的 error 事件,并执行 window.onerror()。
在实际的使用过程中,onerror 主要是来捕获预料之外的错误,而 try-catch 则是用来在可预见情况下监控特定的错误,两者结合使用更加高效。
/**
* @param {String} message 错误信息
* @param {String} source 出错文件
* @param {Number} lineno 行号
* @param {Number} colno 列号
* @param {Object} error Error对象(对象)
*/
window.onerror = function (message, source, lineno, colno, error) {
console.log('捕获到异常:', { message, source, lineno, colno, error });
// window.onerror 函数只有在返回 true 的时候,异常才不会向上抛出,否则即使是知道异常的发生控制台还是会显示 Uncaught Error: xxxxx。
// return true;
};
window.addEventListener
主要用于静态资源加载异常捕获。
Promise Catch
unhandledrejection:
当 Promise 被 reject 且没有 reject 处理器的时候,会触发 unhandledrejection 事件;这可能发生在 window 下,但也可能发生在 Worker 中。 unhandledrejection 继承自 PromiseRejectionEvent,而 PromiseRejectionEvent 又继承自 Event。因此 unhandledrejection 含有 PromiseRejectionEvent 和 Event 的属性和方法。
总结
前端组件/项目中,需要有适当的错误处理过程,否则出现错误,层层上传,没有进行捕获,就会导致页面挂掉。
第四十四式:不做工具人 —— 使用 nodejs 根据配置自动生成文件
笔者在工作中有一个需求是搭建一个 BFF 层项目,实现对每一个接口的权限控制和转发到后端底层接口。因为 BFF 层接口逻辑较少,70%情况下都只是实现一个转发,所以每个文件相似度较高,但因为每个 API 需单独控制权限,所以 API 文件又必须存在,所以使用 nodejs 编写 API 自动化生成脚本,避免进行大量的手动创建文件和复制修改的操作,示例如下:
- 编写自动生成文件的脚本:
// auto.js
const fs = require('fs');
const path = require('path');
const config = require('./apiConfig'); // json配置文件,格式见下面注释内容
// config的格式如下:
// [
// {
// filename: 'querySupplierInfoForPage.js',
// url: '/supplier/rest/v1/supplier/querySupplierInfoForPage',
// comment: '分页查询供应商档案-主信息',
// },
// ]
// 验证数量是否一致
// 也可以在次做一些其他的验证
function verify() {
console.log(
config.length,
fs.readdirSync(path.join(__dirname, '/server/api')).length
);
}
// 生成文件
function writeFileAuto(filePath, item) {
fs.writeFileSync(
filePath,
`/**
* ${item.comment}
*/
const { Controller, Joi } = require('ukoa');
module.exports = class ${item.filename.split('.')[0]} extends Controller {
init() {
this.schema = {
Params: Joi.object().default({}).notes('参数'),
Action: Joi.string().required().notes('Action')
};
}
// 执行函数体
async main() {
const { http_supply_chain } = this.ctx.galaxy;
const [data] = await http_supply_chain("${
item.url
}", this.params.Params, { throw: true });
return this.ok = data.obj;
}
};
`
);
}
function exec() {
config.forEach((item) => {
var filePath = path.join(__dirname, '/server/api/', item.filename);
fs.exists(filePath, function (exists) {
if (exists) {
// 已存在的文件就不要重复生成了,因为也许你已经对已存在的文件做了特殊逻辑处理
//(毕竟只有70%左右的API是纯转发,还有30%左右有自己的处理逻辑)
console.log(`文件${item.filename}已存在`);
} else {
console.log(`创建文件:${item.filename}`);
writeFileAuto(filePath, item);
}
});
});
}
exec();
- 执行脚本,生成文件:
node auto.js
// querySupplierInfoForPage.js
/**
* 分页查询供应商档案-主信息
*/
const { Controller, Joi } = require('ukoa');
module.exports = class querySupplierInfoForPage extends Controller {
init() {
this.schema = {
Params: Joi.object().default({}).notes('参数'),
Action: Joi.string().required().notes('Action'),
};
}
// 执行函数体
async main() {
const { http_supply_chain } = this.ctx.galaxy;
const [data] = await http_supply_chain(
'/supplier/rest/v1/supplier/querySupplierInfoForPage',
this.params.Params,
{ throw: true }
);
return (this.ok = data.obj);
}
};
此处只是抛砖引玉,结合具体业务场景,也许你会为 nodejs 脚本找到更多更好的用法,为前端赋能。
第四十五式:明明元素存在,我的document.getElementsByTagName('video')却获取不到?
- 使用 Chrome 浏览器在线看视频的时候,有些网站不支持倍速播放;有的网站只支持 1.5 和 2 倍速,但是自己更喜欢 1.75 倍;又或者有些网站需要会员才能倍速播放(比如某盘),一般我们可以通过安装相应的浏览器插件解决,如果不愿意安装插件,也可以使用类似
document.getElementsByTagName('video')[0].playbackRate = 1.75(1.75 倍速)的方式实现倍速播放,这个方法在大部分网站上是有效的(当然,如果知道 video 标签的 id 或者 class,通过 id 和 class 来获取元素会更便捷一点),经测试,playbackRate支持的最大倍速 Chrome 下是 16。同时,给playbackRate设置一个小于 1 的值,比如 0.3,可以模拟出类似鬼片的音效。 - 但是在某盘,这种方法却失效了,因为我没有办法获取到 video 元素,审查元素如下:
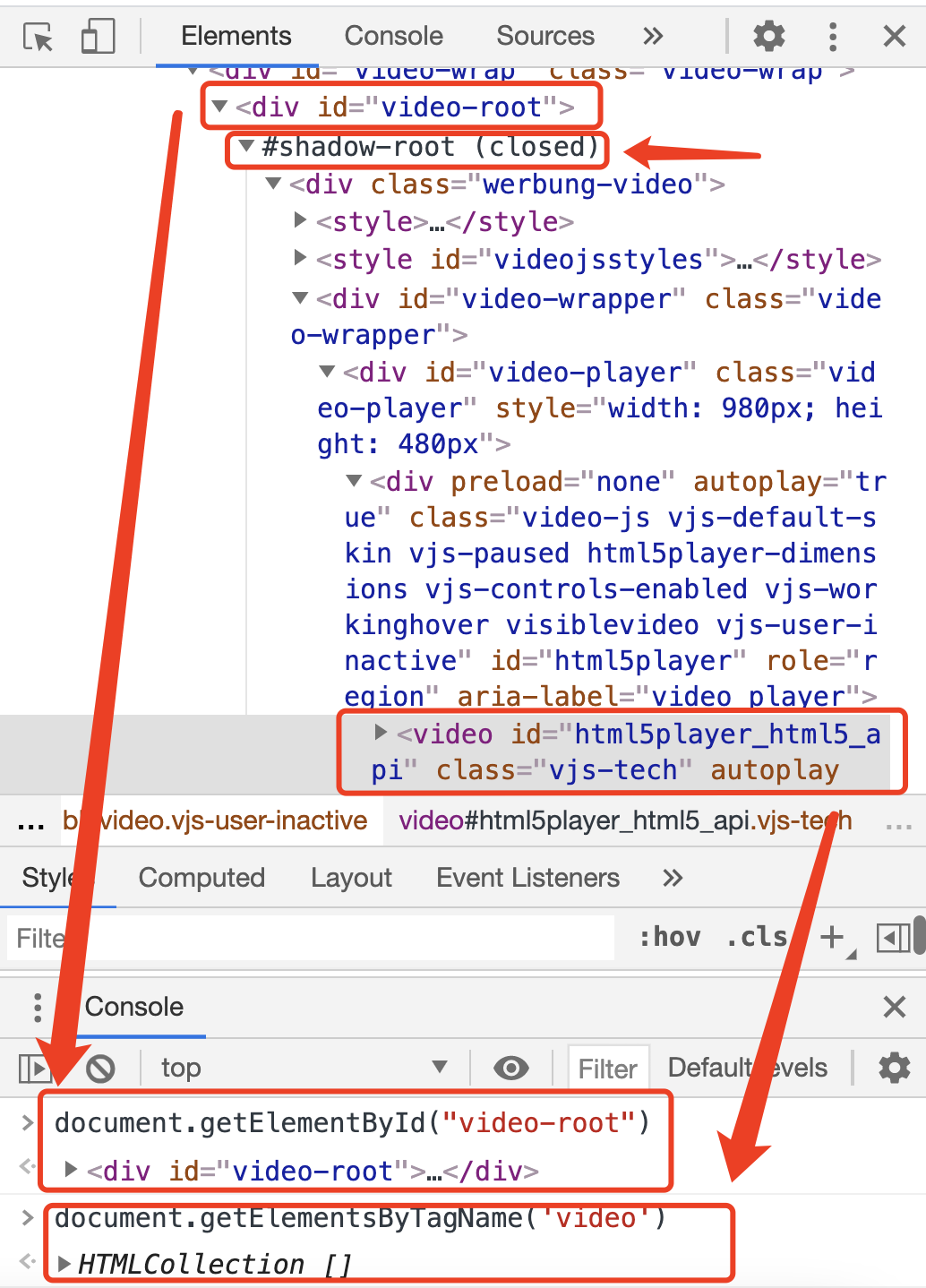
审查元素时,我们发现了#shadow-root (closed)和videojs的存在。也许你还记得,在第六式中我们曾简单探讨过Web Components,其中介绍到attachShadow()方法可以开启 Shadow DOM(这部分 DOM 默认与外部 DOM 隔离,内部任何代码都无法影响外部),隐藏自定义元素的内部实现,我们外部也没法获取到相应元素,如下图所以(点击图片跳转 Web Components 示例代码):
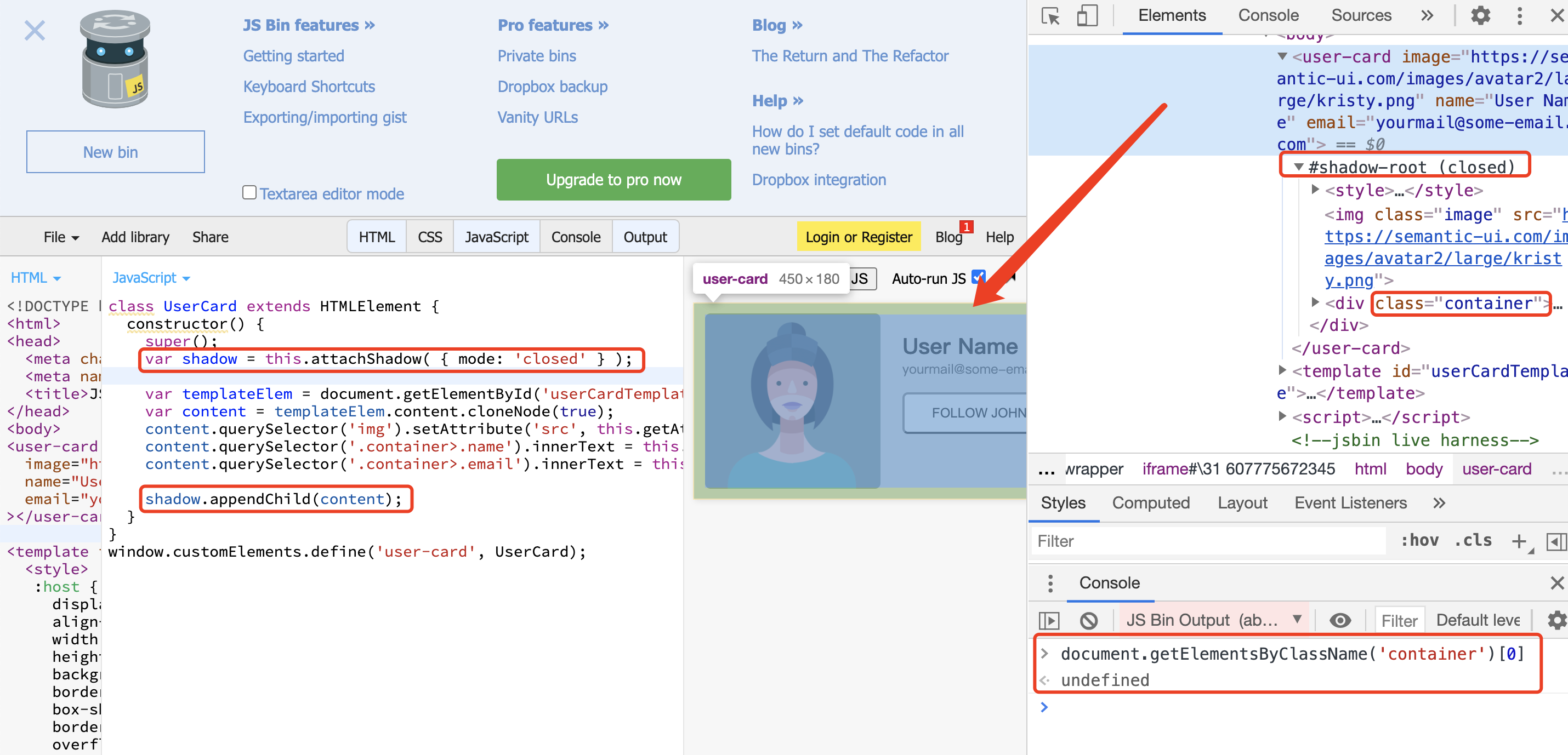
是以,我们可以合理推断,某盘的网页视频播放也使用了类似Element.attachShadow()方法进行了元素隐藏,所以我们无法通过document.getElementsByTagName('video')获取到 video 元素。通过阅读videojs 文档发现,可以通过相应 API 实现自定义倍速播放:
videojs.getPlayers('video-player').html5player.tech_.setPlaybackRate(1.666);
参考资料:百度网盘视频倍速播放方法 | videojs 文档 | Element.attachShadow() | 深入理解 Shadow DOM v1
第四十六式:SQL 也可以 if else? —— 不常写 SQL 的我神奇的知识增加了
在刷 leetcode 的时候遇到一个 SQL 题目627. 变更性别,题目要求:
给定一个 salary 表,有 m = 男性 和 f = 女性 的值。交换所有的 f 和 m 值(例如,将所有 f 值更改为 m,反之亦然)。要求只使用一个更新(Update)语句,并且没有中间的临时表。注意,您必只能写一个 Update 语句,请不要编写任何 Select 语句。
```sql
UPDATE salary
SET
sex = CASE sex
WHEN 'm' THEN 'f'
ELSE 'm'
END;
```
参考资料:SQL 之 CASE WHEN 用法详解
第四十七式:庭院深深深几许,杨柳堆烟,帘幕无重数 —— 如何实现深拷贝?
深拷贝,在前端面试里似乎是一个永恒的话题了,最简单的方法是JSON.stringify()以及JSON.parse(),但是这种方法能正确处理的对象只有 Number, String, Boolean, Array, 扁平对象,不可以拷贝 undefined , function, RegExp 等类型。还有其他一些包括扩展运算符、object.asign、递归拷贝、lodash 库等的实现,网上有很多相关资料和实现,这里不是我们讨论的重点。这次我们来探讨一个新的实现 —— MessageChannel。我们直接看代码:
// 创建一个obj对象,这个对象中有 undefined 和 循环引用
let obj = {
a: 1,
b: {
c: 2,
d: 3,
},
f: undefined,
};
obj.c = obj.b;
obj.e = obj.a;
obj.b.c = obj.c;
obj.b.d = obj.b;
obj.b.e = obj.b.c;
// 深拷贝方法封装
function deepCopy(obj) {
return new Promise((resolve) => {
const { port1, port2 } = new MessageChannel();
port1.postMessage(obj);
port2.onmessage = (e) => resolve(e.data);
});
}
// 调用
deepCopy(obj).then((copy) => {
// 请记住`MessageChannel`是异步的这个前提!
let copyObj = copy;
console.log(copyObj, obj);
console.log(copyObj == obj);
});
我们发现MessageChannel的postMessage传递的数据也是深拷贝的,这和web worker的postMessage一样。而且还可以拷贝 undefined 和循环引用的对象。简单说,MessageChannel创建了一个通信的管道,这个管道有两个端口,每个端口都可以通过postMessage发送数据,而一个端口只要绑定了onmessage回调方法,就可以接收从另一个端口传过来的数据。
需要说明的一点是:
MessageChannel在拷贝有函数的对象时,还是会报错。
第四十八式:换了电脑,如何使用 VSCode 保存插件配置?
也许每一个冇得感情的 API 调用工程师在使用 VSCode 进行开发时,都有自己的插件、个性化配置以及代码片段等,使用 VSCode 不用登陆,不用注册账号,确实很方便,但这同时也带来一个问题:如果你有多台电脑,比如家里一个、公司一个,都会用来开发;又或者,你离职入职了新的公司。此时,我们就需要从头再次配置一遍 VSCode,包括插件、配置、代码片段,如此反复,也许真的会崩溃。其实 VSCode 提供了 setting sync 插件,很方便我们同步插件配置。具体使用如下:
- 在 VSCode 中搜索 Settings Sync 并进行安装;
- 安装后,摁下 Ctrl(mac 为 command)+ Shift + P 打开控制面板,搜索 Sync,选择 Sync: Update/Upload Settings 可以上传你的配置,选择 Sync: Download Settings 会下载远程配置;
- 如果你之前没有使用过 Settings Sync,在上传配置的时候,会让你在 Github 上创建一个授权码,允许 IDE 在你的 gist 中创建资源;下载远程配置,你可以直接将 gist 的 id 填入。
- 下载后等待安装,然后重启即可。
如此以来,我们就可以在多台设备间同步配置了。
第四十九式:防止对象被篡改,可以试试 Object.seal 和 Object.freeze
有时候你可能怕你的对象被误改了,所以需要把它保护起来。
Object.seal防止新增和删除属性
通常,一个对象是可扩展的(可以添加新的属性)。Object.seal()方法封闭一个对象会让这个对象变的不能添加新属性,且所有已有属性会变的不可配置。属性不可配置的效果就是属性变的不可删除,以及一个数据属性不能被重新定义成为访问器属性,或者反之。当前属性的值只要原来是可写的就可以改变。尝试删除一个密封对象的属性或者将某个密封对象的属性从数据属性转换成访问器属性,结果会静默失败或抛出 TypeError。
数据属性包含一个数据值的位置,在这个位置可以读取和写入值。访问器属性不包含数据值。它包含一对 getter 和 setter 函数。当读取访问器属性时,会调用 getter 函数并返回有效值;当写入访问器属性时,会调用 setter 函数并传入新值,setter 函数负责处理数据。
const person = {
name: 'jack',
};
Object.seal(person);
delete person.name;
console.log(person); // {name: "jack"}
Object.freeze冻结对象Object.freeze()方法可以冻结一个对象。一个被冻结的对象再也不能被修改;冻结了一个对象则不能向这个对象添加新的属性,不能删除已有属性,不能修改该对象已有属性的可枚举性、可配置性、可写性,以及不能修改已有属性的值。此外,冻结一个对象后该对象的原型也不能被修改。freeze() 返回和传入的参数相同的对象。
const obj = {
prop: 42,
};
Object.freeze(obj);
obj.prop = 33;
// Throws an error in strict mode
console.log(obj.prop);
// expected output: 42
Tips:
Object.freeze是浅冻结,即只冻结一层,要使对象不可变,需要递归冻结每个类型为对象的属性(深冻结)。使用Object.freeze()冻结的对象中的现有属性值是不可变的。用Object.seal()密封的对象可以改变其现有属性值。同时可以使用 Object.isFrozen、Object.isSealed、Object.isExtensible 判断当前对象的状态。
-
Object.defineProperty冻结单个属性:设置 enumable/writable 为 false,那么这个属性将不可遍历和写 -
参考资料:JS 高级技巧 | javascript 的数据属性和访问器属性 | Object.freeze() | Object.seal() | 深入浅出 Object.defineProperty()
第五十式:不随机的随机数 —— 我们都知道Math.random是伪随机的,那如何得到密码学安全的随机数
在 JavaScript 中产生随机数的方式是调用 Math.random,这个函数返回[0, 1)之间的数字,我们通过对Math.random的包装处理,可以得到我们想要的各种随机值。
- 怎么实现一个随机数发生器
// from stackoverflow
// 下面的实现还是很随机的
let seed = 1;
function random() {
let x = Math.sin(seed++) * 10000;
return x - Math.floor(x);
}
随机数发生器函数需要一个种子 seed,每次调用 random 函数的时候种子都会发生变化。因为random()是一个没有输入的函数,不管执行多少次,其运行结果都是一样的,所以需要有一个不断变化的入参,这个入参就叫种子,每运行一次种子就会发生一次变化。所以我们可以借助以上思路实现自己的随机数发生器(或许有些场合,我们不必管他是不是真的是随机的,再或者就是要让他不随机呢)。
- 为什么说 Math.random 是不安全的呢?
V8 源码显示 Math.random 种子的可能个数为 2 ^ 64, 随机算法相对简单,只是保证尽可能的随机分布。我们知道扑克牌有 52 张,总共有 52! = 2 ^ 226 种组合,如果随机种子只有 2 ^ 64 种可能,那么可能会有大量的组合无法出现。
从 V8 里 Math.random 的实现逻辑来看,每次会一次性产生 128 个随机数,并放到 cache 里面,供后续使用,当 128 个使用完了再重新生成一批随机数。所以 Math.random 的随机数具有可预测性,这种由算法生成的随机数也叫伪随机数。只要种子确定,随机算法也确定,便能知道下一个随机数是什么。具体可参考随机数的故事。
Crypto.getRandomValues()
Crypto.getRandomValues() 方法让你可以获取符合密码学要求的安全的随机值。传入参数的数组被随机值填充(在加密意义上的随机)。window.crypto.getRandomValue的实现在 Safari,Chrome 和 Opera 浏览器上是使用带有 1024 位种子的ARC4流密码。
var array = new Uint32Array(10);
window.crypto.getRandomValues(array);
console.log('Your lucky numbers:');
for (var i = 0; i < array.length; i++) {
console.log(array[i]);
}
参考资料:随机数的故事 | Crypto.getRandomValues() | 如何使用 window.crypto.getRandomValues 在 JavaScript 中调用扑克牌?
第五十一式:forEach 只是对 for 循环的简单封装?你理解的 forEach 可能并不正确
我们先看看下面这个forEach的实现:
Array.prototype.forEachCustom = function (fn, context) {
context = context || arguments[1];
if (typeof fn !== 'function') {
throw new TypeError(fn + 'is not a function');
}
for (let i = 0; i < this.length; i++) {
fn.call(context, this[i], i, this);
}
};
我们发现,上面的代码实现其实只是对 for 循环的简单封装,看起来似乎没有什么问题,因为很多时候,forEach 方法是被用来代替 for 循环来完成数组遍历的。其实不然,我们再看看下面的测试代码:
// 示例1
const items = ['', 'item2', 'item3', , undefined, null, 0];
items.forEach((item) => {
console.log(item); // 依次打印:'',item2,item3,undefined,null,0
});
items.forEachCustom((item) => {
console.log(item); // 依次打印:'',item2,item3,undefined,undefined,null,0
});
// 示例2
let arr = new Array(8);
arr.forEach((item) => {
console.log(item); // 无打印输出
});
arr[1] = 9;
arr[5] = 3;
arr.forEach((item) => {
console.log(item); // 打印输出:9 3
});
arr.forEachCustom((item) => {
console.log(item); // 打印输出:undefined 9 undefined*3 3 undefined*2
});
我们发现,forEachCustom 和原生的 forEach 在上面测试代码的执行结果并不相同。关于各个新特性的实现,其实我们都可以在 ECMA 文档中找到答案:
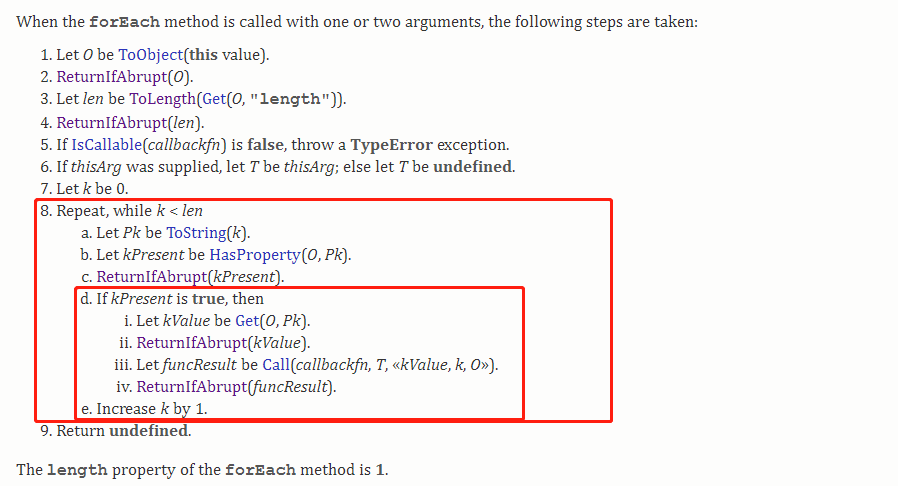
我们可以发现,真正执行遍历操作的是第 8 条,通过一个 while 循环来实现,循环的终止条件是前面获取到的数组的长度(也就是说后期改变数组长度不会影响遍历次数),while 循环里,会先把当前遍历项的下标转为字符串,通过 HasProperty 方法判断数组对象中是否有下标对应的已初始化的项,有的话,获取对应的值,执行回调,没有的话,不会执行回调函数,而是直接遍历下一项。
如此看来,forEach 不对未初始化的值进行任何操作(稀疏数组),所以才会出现示例 1 和示例 2 中自定义方法打印出的值和值的数量上均有差别的现象。那么,我们只需对前面的实现稍加改造,即可实现一个自己的 forEach 方法:
Array.prototype.forEachCustom = function (fn, context) {
context = context || arguments[1];
if (typeof fn !== 'function') {
throw new TypeError(fn + 'is not a function');
}
let len = this.length;
let k = 0;
while (k < len) {
// 下面是两种实现思路,ECMA文档使用的是HasProperty,在此,使用in应该比hasOwnProperty更确切
// if (this.hasOwnProperty(k)) {
// fn.call(context, this[k], k, this);
// };
if (k in this) {
fn.call(context, this[k], k, this);
}
k++;
}
};
再次运行示例 1 和示例 2 的测试用列,发现输出和原生 forEach 一致。
通过文档,我们还发现,在迭代前 while 循环的次数就已经定了,且执行了 while 循环,不代表就一定会执行回调函数,我们尝试在迭代时修改数组:
// 示例3
var words = ['one', 'two', 'three', 'four'];
words.forEach(function (word) {
console.log(word); // one,two,four(在迭代过程中删除元素,导致three被跳过,因为three的下标已经变成1,而下标为1的已经被遍历了过)
if (word === 'two') {
words.shift();
}
});
words = ['one', 'two', 'three', 'four']; // 重新初始化数组进行forEachCustom测试
words.forEachCustom(function (word) {
console.log(word); // one,two,four
if (word === 'two') {
words.shift();
}
});
// 示例4
var arr = [1, 2, 3];
arr.forEach((item) => {
if (item == 2) {
arr.push(4);
arr.push(5);
}
console.log(item); // 1,2,3(迭代过程中在末尾增加元素,并不会使迭代次数增加)
});
arr = [1, 2, 3];
arr.forEachCustom((item) => {
if (item == 2) {
arr.push(4);
arr.push(5);
}
console.log(item); // 1,2,3
});
以上过程启示我们,在工作中碰见和我们预期存在差异的问题时,我们完全可以去ECMA 官方文档中寻求答案。
这里可以参考笔者之前的一篇文章:JavaScript 很简单?那你理解的 forEach 真的对吗?
第五十二式:Git 文件名大小写敏感问题,你栽过坑吗?
笔者大约两年前刚用 Mac 开发前端时曾经遇到一个坑:代码在本地运行 ok,但是发现 push 到 git,自动部署后报错了,排查了很久,最后发现有个文件名没有注意大小写,重命名了该文件,但是 git 没有识别到这个更改,导致自动部署后找不到这个文件。解决办法如下:
- 查看 git 的设置:
git config --get core.ignorecase - git 默认是不区分大小的,因此当你修改了文件名/文件夹的大小写后,git 并不会认为你有修改(git status 不会提示你有修改)
- 更改设置解决:
git config core.ignorecase false
这么以来,git 就能识别到文件名大小写的更改了。在次建议,平时我们在使用 React 编写项目时,文件名最后保持首字母大写。
第五十三式:你看到的 0.1 其实并不是 0.1 —— 老生长谈的 0.1 + 0.2 !== 0.3,这次我们说点不一样的
0.1 + 0.2 !== 0.3是一个老生长谈的问题来,想必你也明白其中的根源:JS 采用 IEEE 754 双精度版本(64 位),并且只要采用 IEEE 754 的语言都有这样的问题。详情可查看笔者之前的一篇文章0.1 + 0.2 != 0.3 背后的原理,本节我们只探讨解法。
- 既然 IEEE 754 存在精度问题,那为什么 x=0.1 能得到 0.1?
因为在浮点数的存储中, mantissa(尾数) 固定长度是 52 位,再加上省略的一位,最多可以表示的数是 2^53=9007199254740992,对应科学计数尾数是 9.007199254740992,这也是 JS 最多能表示的精度。它的长度是 16,所以可以使用 toPrecision(16) 来做精度运算,超过的精度会自动做凑整处理。于是就有:
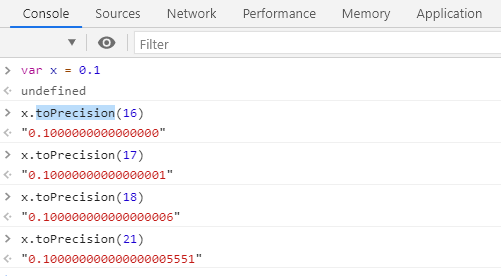
0.10000000000000000555.toPrecision(16)
// 返回 0.1000000000000000,去掉末尾的零后正好为 0.1
// 但你看到的 `0.1` 实际上并不是 `0.1`。不信你可用更高的精度试试:
0.1.toPrecision(21) = 0.100000000000000005551
toFixed设置精确位数
toFixed() 方法可把 Number 四舍五入为指定小数位数的数字,语法:NumberObject.toFixed(num)。
// 保留两位小数
console.log((0.1 + 0.2).toFixed(2)); // 0.30
Number.EPSILON
想必你还有印象,在高中数学或者大学数学分析、数值逼近中,在证明两个值相等的时候,我们会让他们的差去逼近一个任意小的数。那么,在此自然可以想到让 0.1 + 0.2 的和减去 0.3 小于一个任意小的数,比如说我们可以通过他们差值是否小于 0.0000000001 来判断他们是否相等。
其实 ES6 已经在 Number 对象上面,新增一个极小的常量 Number.EPSILON。根据规格,它表示 1 与大于 1 的最小浮点数之间的差。Number.EPSILON 实际上是 JavaScript 能够表示的最小精度。误差如果小于这个值,就可以认为已经没有意义了,即不存在误差了。
console.log(0.1 + 0.2 - 0.3 < Number.EPSILON); // true
- 转换成整数或者字符串再进行求和运算
为了避免产生精度差异,我们要把需要计算的数字乘以 10 的 n 次幂,换算成计算机能够精确识别的整数,然后再除以 10 的 n 次幂,大部分编程语言都是这样处理精度差异的,我们就借用过来处理一下 JS 中的浮点数精度误差。
传入 n 次幂的 n 值:
formatNum = function (f, digit) {
var m = Math.pow(10, digit);
return parseInt(f * m, 10) / m;
};
var num1 = 0.1;
var num2 = 0.2;
console.log(num1 + num2);
console.log(formatNum(num1 + num2, 1));
自动计算 n 次幂的 n 值:
/**
* 精确加法
*/
function add(num1, num2) {
const num1Digits = (num1.toString().split('.')[1] || '').length;
const num2Digits = (num2.toString().split('.')[1] || '').length;
const baseNum = Math.pow(10, Math.max(num1Digits, num2Digits));
return (num1 * baseNum + num2 * baseNum) / baseNum;
}
add(0.1, 0.2); // 0.3
- 使用类库:
通常这种对精度要求高的计算都应该交给后端去计算和存储,因为后端有成熟的库来解决这种计算问题。前端也有几个不错的类库:
第五十四式:发版提醒全靠吼 —— 如何纯前端实现页面检测更新并提示?
开发过程中,经常遇到页面更新、版本发布时,需要告诉使用人员刷新页面的情况,甚至有些运营、测试人员觉得切换一下菜单再切回去就是更新了 web 页面资源,有的分不清普通刷新和强刷的区别,所以实现了一个页面更新检测功能,页面更新了自动提示使用人员刷新页面。
基本思路为:使用 webpack 配置打包编译时在 js 文件名里添加 hash,然后使用 js 向${window.location.origin}/index.html发送请求,解析出 html 文件里引入的 js 文件名称 hash,对比当前 js 的 hash 与新版本的 hash 是否一致,不一致则提示用户更新版本。
// uploadUtils.jsx
import React from 'react';
import axios from 'axios';
import { notification, Button } from 'antd';
// 弹窗是否已展示(可以改用闭包、单例模式等实现,看起来会更有逼格一点)
let uploadNotificationShow = false;
// 关闭notification
const close = () => {
uploadNotificationShow = false;
};
// 刷新页面
const onRefresh = (new_hash) => {
close();
// 更新localStorage版本号信息
window.localStorage.setItem('XXXSystemFrontVesion', new_hash);
// 刷新页面
window.location.reload(true);
};
// 展示提示弹窗
const openNotification = (new_hash) => {
uploadNotificationShow = true;
const btn = (
<Button type='primary' size='small' onClick={() => onRefresh(new_hash)}>
确认更新
</Button>
);
// 这里不自动执行更新的原因是:
// 考虑到也许此时用户正在使用系统甚至填写一个很长的表单,那你直接刷新了页面,或许会被掐死的,哈哈
notification.open({
message: '版本更新提示',
description: '检测到系统当前版本已更新,请刷新后使用。',
btn,
// duration为0时,notification不自动关闭
duration: 0,
onClose: close,
});
};
// 获取hash
export const getHash = () => {
// 如果提示弹窗已展示,就没必要执行接下来的检查逻辑了
if (!uploadNotificationShow) {
// 在 js 中请求首页地址,这样不会刷新界面,也不会跨域
axios
.get(`${window.location.origin}/index.html?time=${new Date().getTime()}`)
.then((res) => {
// 匹配index.html文件中引入的js文件是否变化(具体正则,视打包时的设置及文件路径而定)
let new_hash = res.data && res.data.match(/\/static\/js\/main.(.*).js/);
// console.log(res, new_hash);
new_hash = new_hash ? new_hash[1] : null;
// 查看本地版本
let old_hash = localStorage.getItem('XXXSystemFrontVesion');
if (!old_hash) {
// 如果本地没有版本信息(第一次使用系统),则直接执行一次额外的刷新逻辑
onRefresh(new_hash);
} else if (new_hash && new_hash != old_hash) {
// 本地已有版本信息,但是和新版不同:版本更新,弹出提示
openNotification(new_hash);
}
});
}
};
使用示例:
import { getHash } from './uploadUtils';
let timer = null;
componentDidMount() {
getHash();
timer = setInterval(() => {
getHash();
// 10分钟检测一次
}, 600000)
}
componentWillUnmount () {
// 页面卸载时清除
clearInterval(timer);
}
结合Console Importer直接在控制台面板查看:
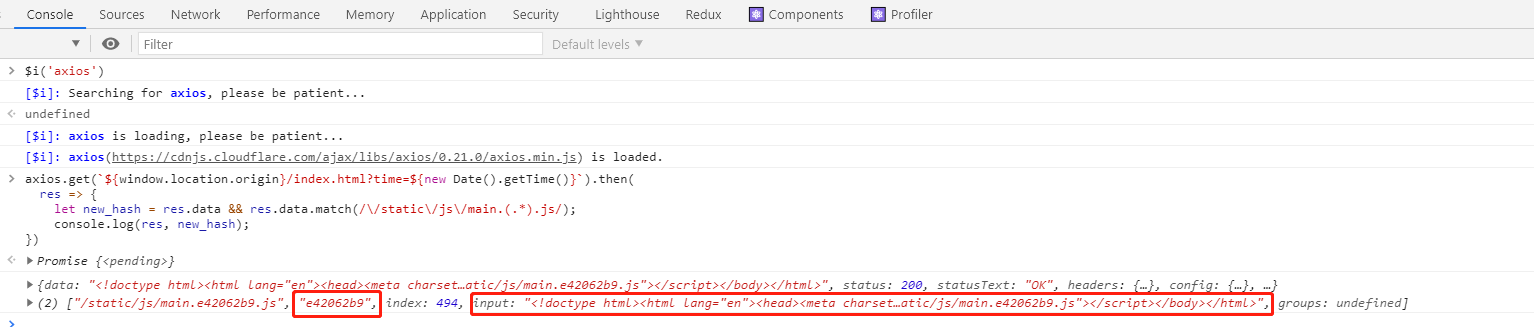
你也完全可以在上面的方法上更上一层楼,build 的时候,在 index.html 同级目录下,自动生成一个 json 文件,包含新的文件的 hash 信息,检查版本的时候,就只需直接请求这个 json 文件进行对比了,减少数据的冗余。
参考资料:纯前端实现页面检测更新提示
